Making Generative AI Effectively Multilingual at Scale
The benefits and value of revolutionary technology like GPT-4 are much greater for English speakers over other languages. T-LM is committed to widening the reach of optimized GPT technology to non-English speakers across the globe, thereby elevating user satisfaction and reducing usage expenses.

The internet is the primary source of information, economic opportunity, and community for many around the world. However, the automated systems that increasingly mediate our interactions online — such as chatbots, content moderation systems, and search engines — are primarily designed for and work far more effectively in English than in the world’s other 7,000 languages
It is clear to anyone who works with LLMs and multilingual models, that there are now many powerful and impressive LLM models available for generating natural and fluent texts in English. While there has been substantial hype around the capabilities and actual potential value of a wide range of applications and use cases, the benefits have been most pronounced for English-speaking users.
It is also now increasingly being understood that achieving the same level of quality and performance for other languages, even the ones that are widely spoken, is not an easy task. AI chatbots are less fluent in languages other than English and are thus threatening to amplify the existing language bias in global commerce, knowledge access, basic internet research, and innovation.
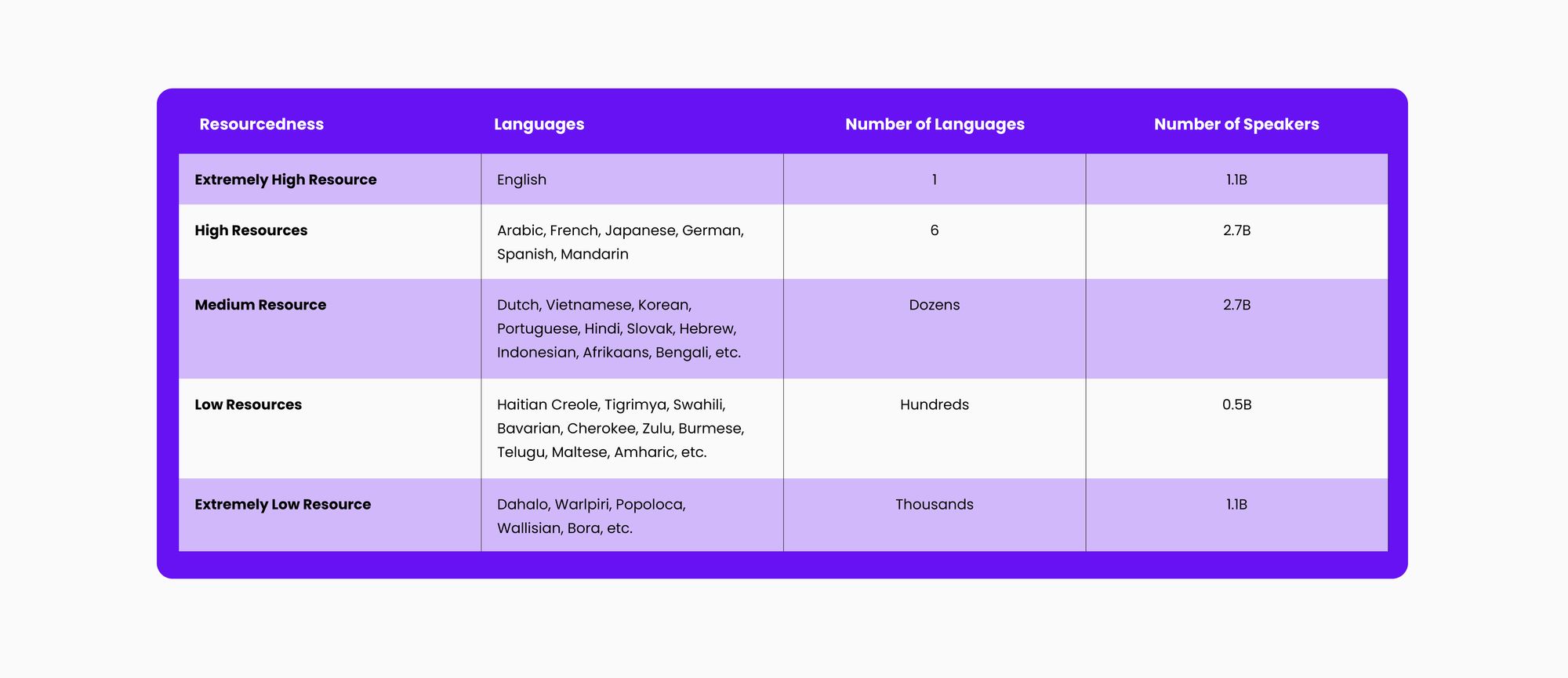
In the past, it has been difficult to develop AI systems — and especially large language models — in languages other than English because of what is known as the resourcedness gap.
The resourcedness gap describes the asymmetry in the availability of high-quality digitized text that can serve as training data for a large language model and generative AI solutions in general.
English is an extremely highly resourced language, whereas other languages, including those used predominantly in the Global South, often have fewer examples of high-quality text (if any at all) on which to train language models.
English-speaking users have a better user experience with generative AI than users who speak other languages, and the current models will only amplify this English bias further.
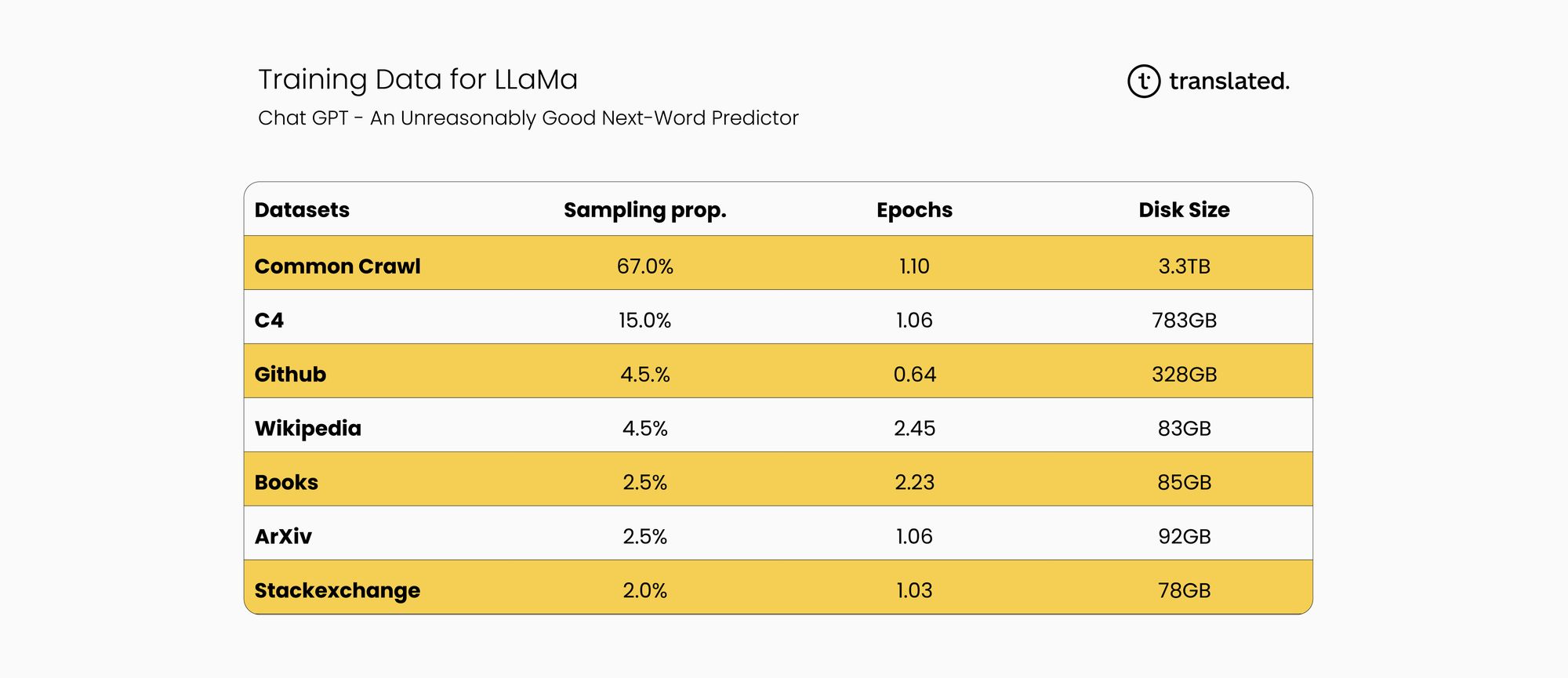
It is estimated that although GPT-3's training data consists of > 90% English text it did include some foreign language text, but not enough to ensure that model performance across different languages is consistent. GPT-3 was the foundation model used to build ChatGPT and though we do not know what data was used in GPT-4 we can safely assume that no major sources of non-English data have been acquired, primarily because it is not easily available.
Source: Lost in Translation Large Language Models in Non-English Content Analysis
Researchers like Pascale Fung and others have pointed out the difficulty for many global customers because of the dominance of English in eCommerce. It is much easier to get information about products in English in online marketplaces than it is in any other language.
Fung, director of the Center for AI Research at the Hong Kong University of Science and Technology, who herself speaks seven languages, sees this bias even in her research field. “If you don’t publish papers in English, you’re not relevant,” she says. “Non-English speakers tend to be punished professionally.”
The following table describes the sources data for the training corpus of GPT-3 which is the data foundation for ChatGPT:
|
Datasets |
Quantity (Tokens) |
Weight in Training Mix |
Epochs elapsed when
training for 300 BN tokens |
|
Common Crawl
(filtered) |
410 BN |
60% |
0.44 |
|
WebText2 |
19 BN |
22% |
2.90 |
|
Books1 |
12 BN |
8% |
1.90 |
|
Books2 |
55 BN |
8% |
0.43 |
|
Wikipedia |
3 BN |
3% |
3.40 |
It is useful to understand what data has been used to train GPT-3. This overview provides some valuable details that also help us understand the English bias and US-centric perspective that these models have.
Fung and others are part of a global community of AI researchers testing the language skills of ChatGPT and its rival chatbots and sounding the alarm about providing evidence that they are significantly less capable in languages other than English.
- ChatGPT still lacks the ability to understand and generate sentences in low-resource languages. The performance disparity in low-resource languages limits the diversity and inclusivity of NLP.
- ChatGPT also lacks the ability to translate sentences in non-Latin script languages, despite the languages being considered high-resource.
“One of my biggest concerns is we’re going to exacerbate the bias for English and English speakers,” says Thien Huu Nguyen, a University of Oregon computer scientist who is also a leading researcher raising awareness about the often impoverished experience non-English speakers routinely experience with generative AI. Nguyen specifically points out:
ChatGPT’s performance is generally better for English than for other languages, especially for higher-level tasks that require more complex reasoning abilities (e.g., named entity recognition, question answering, common sense reasoning, and summarization). The performance differences can be substantial for some tasks and lower-resource languages.
- ChatGPT can perform better with English prompts even though the task and input texts are intended for other languages.
- ChatGPT performed substantially worse at answering factual questions or summarizing complex text in non-English languages and was more likely to fabricate information.
The research tends to point clearly to the English bias of the most popular LLMs and state: The AI systems are good at translating other languages into English, but they struggle with rewriting English into other languages—especially for languages like Korean, with non-Latin scripts.
“51.3% of pages are hosted in the United States. The countries with the estimated 2nd, 3rd, and 4th largest English-speaking populations—India, Pakistan, Nigeria, and The Philippines—have only 3.4%, 0.06%, 0.03%, 0.1% the URLs of the United States, despite having many tens of millions of English speakers.”
(Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus, 2021, p. 4)
The chart below displays a deeper dive into the linguistic makeup of the Common Crawl data by the Common Sense Advisory research team.
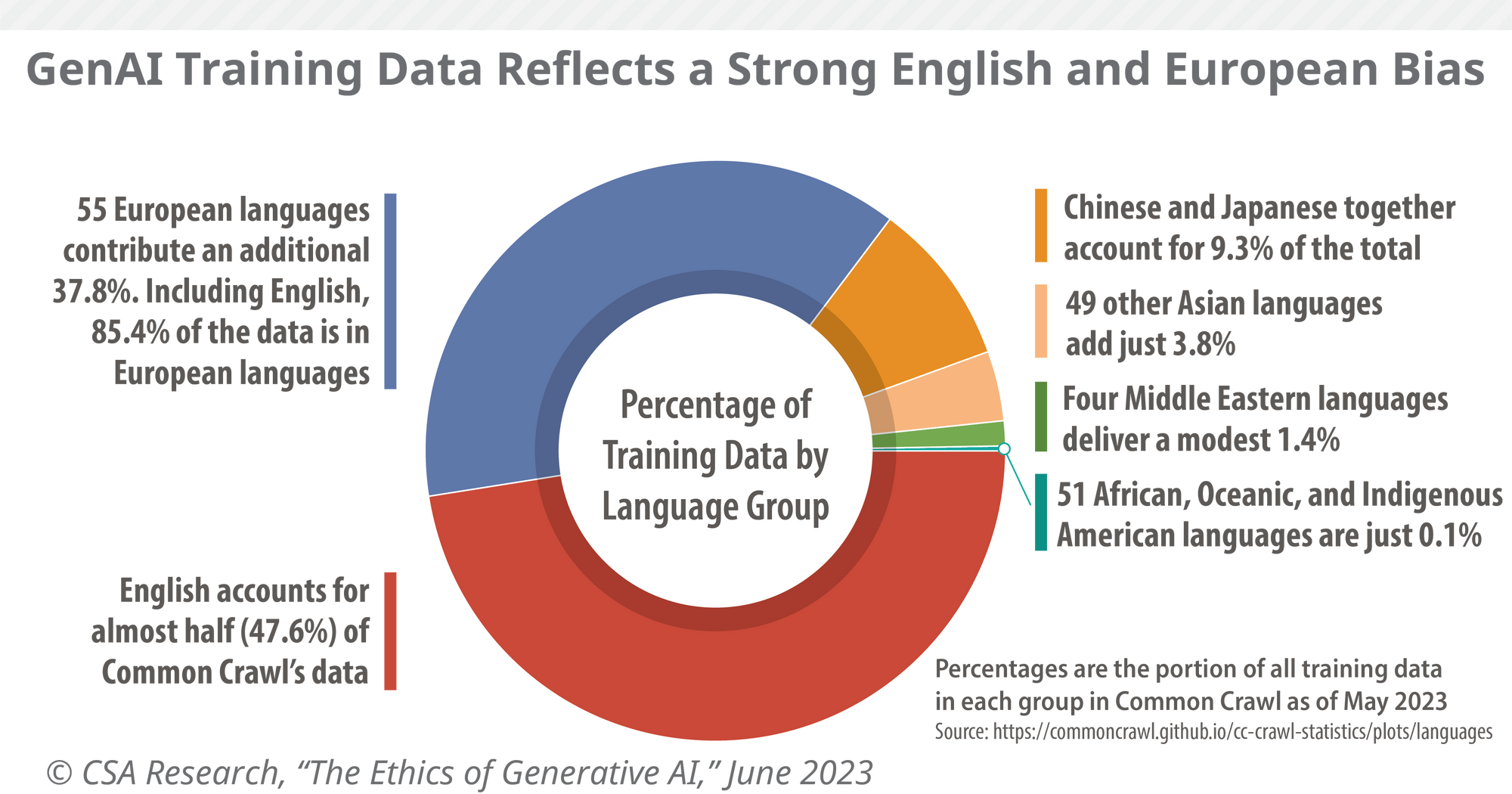
Recently though, researchers and technology companies have attempted to extend the capabilities of large language models into languages other than English by building what are called multilingual language models. Instead of being trained on text from only one language, multilingual language models are trained on text from dozens or hundreds of languages at once.
Researchers posit that multilingual language models can infer connections between languages, allowing them to apply word associations and underlying grammatical rules learned from languages with more text data available to train on (in particular English) to those with less.
Languages vary widely in resourcedness, or the volume, quality, and diversity of text data they have available to train language models on. English is the highest-resourced language by multiple orders of magnitude, but Spanish, Chinese, German, and a handful of other languages are sufficiently high resources enough to build language models.
Though they are still expected to be lower in quality than English language models. Medium resource languages, with fewer but still high-quality data sets, such as Russian, Hebrew, and Vietnamese, and low resource languages, with almost no training data sets, such as Amharic, Cherokee, and Haitian Creole, have too little text for training large language models
However, there are many challenges and complexities involved in developing multilingual and multicultural LLMs that can cater to the diverse needs and preferences of different communities. Multilingual language models are still usually trained disproportionately on English language text and thus end up transferring values and assumptions encoded in English into other language contexts where they may not belong.
Most remedial approaches to address the English bias rely on the acquisition of large amounts of non-English data to be added to the core training data to reduce the English bias in current LLMs; data which is not easily found or often non-existent. Certainly not at the scale, volume, and diversity that English training data exists.
English is the closest thing there is to a global lingua franca. It is the dominant language in science, popular culture, higher education, international politics, and global capitalism; it has the most total speakers and the third-most first-language speakers.
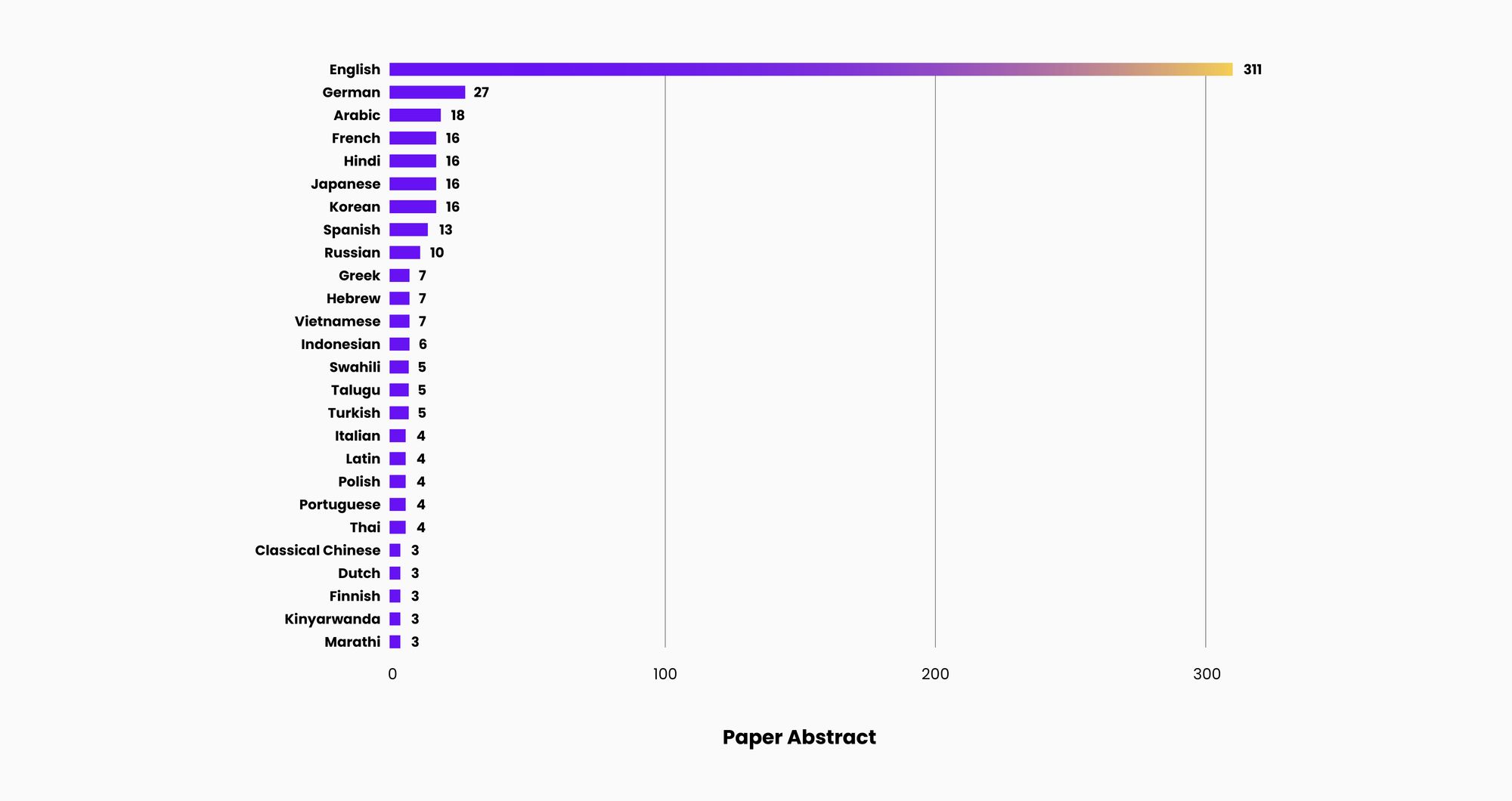
The bias in the NLP research community is evident in the chart below. ACL papers are more likely to be published in English than any other language by a factor of 11X to 80X!
Source: http://stats.aclrollingreview.org/submissions/linguistic-diversity/
Recent US congressional hearings also focused on this language-bias problem when Senator Alex Padilla (a native Spanish speaker) of California questioned the CEO of OpenAI about improving the experience for the growing population of non-English users even in the US, and said: “These new technologies hold great promise for access to information, education, and enhanced communication, and we must ensure that language doesn’t become a barrier to these benefits.”
However, the fact remains, and OpenAI clearly states that the majority of the underlying training data used to power ChatGPT (and most other LLMs) came from English and that the company’s efforts to fine-tune and study the performance of the model is primarily focused on English “with a US-centric point of view.”
This also results in the models performing better on tasks that involve going from Language X to English than on tasks that involve going from English to Language X. Because of the data scarcity and substantial costs involved in correcting this it is not likely to change soon.
Because the training text data sets used to train GPT models also have some other languages mixed in, the generative AI models do pick up some capability in other languages. However, their knowledge is not necessarily comprehensive or complete enough, and in a development approach that implicitly assumes that scale is all you need, most languages simply do not have enough scale in training data to perform at the same levels as English.
This is likely to change over time to some extent, and already the Google PaLM model claims to be able to handle more languages, but early versions show only very small incremental improvements in a very few select languages.
Each new language that is "properly supported" will require a separate set of guardrails and controls to minimize problematic model behavior.
Thus, beyond the monumental task of finding massive amounts of non-English text and re-training the base generative AI model from scratch, researchers are also trying other approaches e.g., creating new data sets of non-English text to try to accelerate the development of truly multilingual models, or by generating synthetic data by using what is available in high resource languages like English or Chinese, which are both less effective than simply having the adequate data volume in the low-resource language in the first place.
Nguyen and other researchers say they would also like to see AI developers pay more attention to the data sets they feed into their models and better understand how that affects each step in the building process, not just the final results. So far, the data and which languages end up in models has been a "random process," Nguyen says.
So when you make a prompt request in English, it draws primarily from all the English language data it has. When you make a request in traditional Chinese, it draws primarily from the Chinese language data it has. How and to what extent these two piles of data inform one another or the resulting outcome is not clear, but at present, experiments show that they at least are quite independent.
The training data for these models were collected through long-term web crawling initiatives, and a lot of it was pretty random. More rigorous controls to reach certain thresholds of content for each language -as Google tried to do with PaLM- could improve the quality of non-English output. It is also possible that more carefully collected and curated data that is better balanced linguistically could improve performance across more languages.
The T-LM (Translated Language Model) Offering
The fundamental data acquisition and limited and sub-optimal accessibility problems described above could take years to resolve. Thus, Translated Srl is introducing a way to address the needs of a larger global population interested in using GPT-4 for content creation, content analysis, basic research, and content refinement in their preferred language.
The following chart shows the improved performance available with T-LM across several languages. Users can expect the performance improvements to continue to increase and improve as they provide corrective feedback daily.
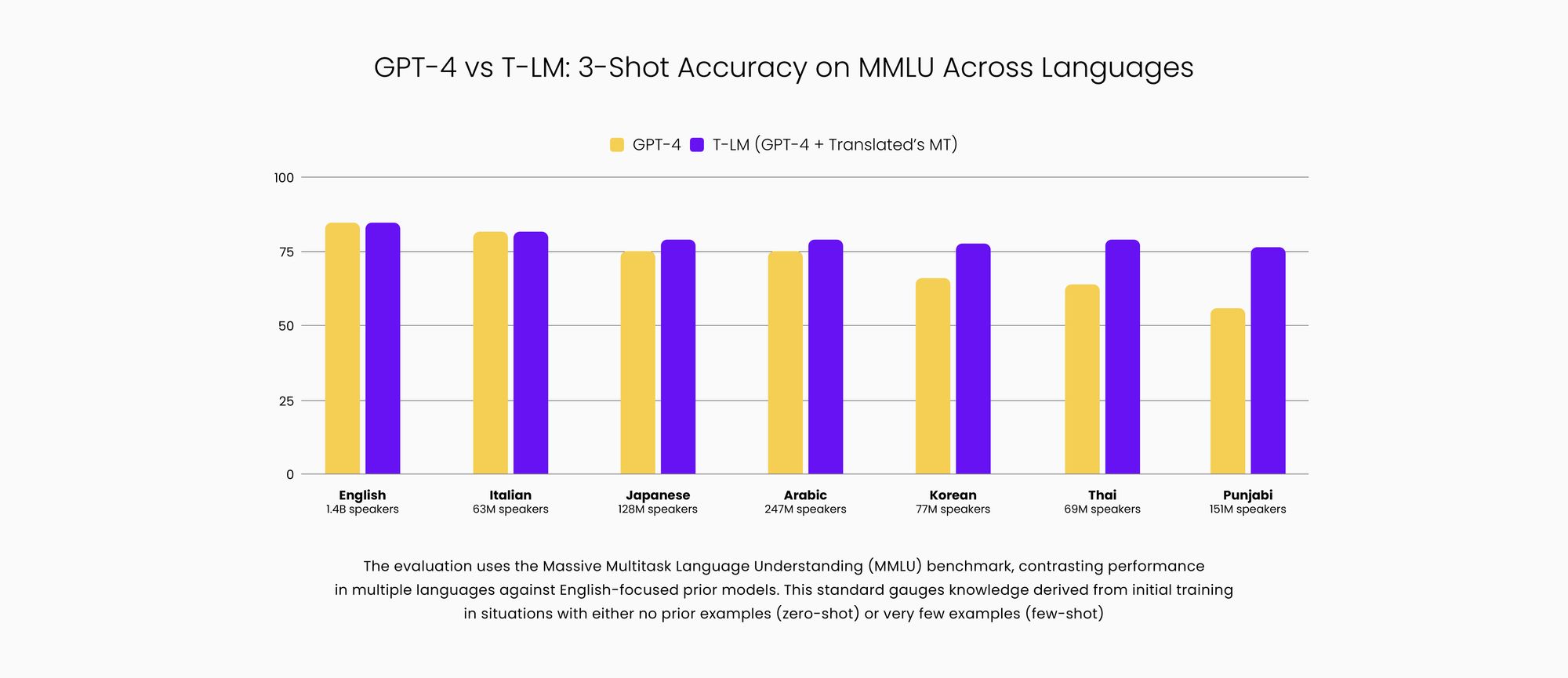
Combining the power of the state-of-the-art adaptive machine translation technology with OpenAI's latest language model will result in empowering users across 200 languages to engage and explore the capabilities of GPT-4 in a preferred non-English language and achieve superior performance.
T-LM will help unlock the full potential of GPT-4 for businesses around the world. It provides companies with a cost-effective solution to create and restructure content and do basic content research in 200 languages, bridging the performance gap between GPT-4 in English and non-English languages.
A detailed overview of the 200 specific languages and their importance in the changing global dynamics is described here.
Many users have documented and reported sub-optimal performance when searching with Bing Chat when they query in Spanish rather than English.
In a separate dialog, when queried in English, Bing Chat correctly identified Thailand as the rumored location for the next set of the TV show White Lotus, but provided “somewhere in Asia” when the query was translated to Spanish, says Solis, who runs a consultancy called Orainti that helps websites increase visits from search engines.
Other discussions point out that ChatGPT performs sub-optimally in most languages other than English. Techcrunch also ran some tests to demonstrate that ChatGPT has lesser performance in non-English languages.

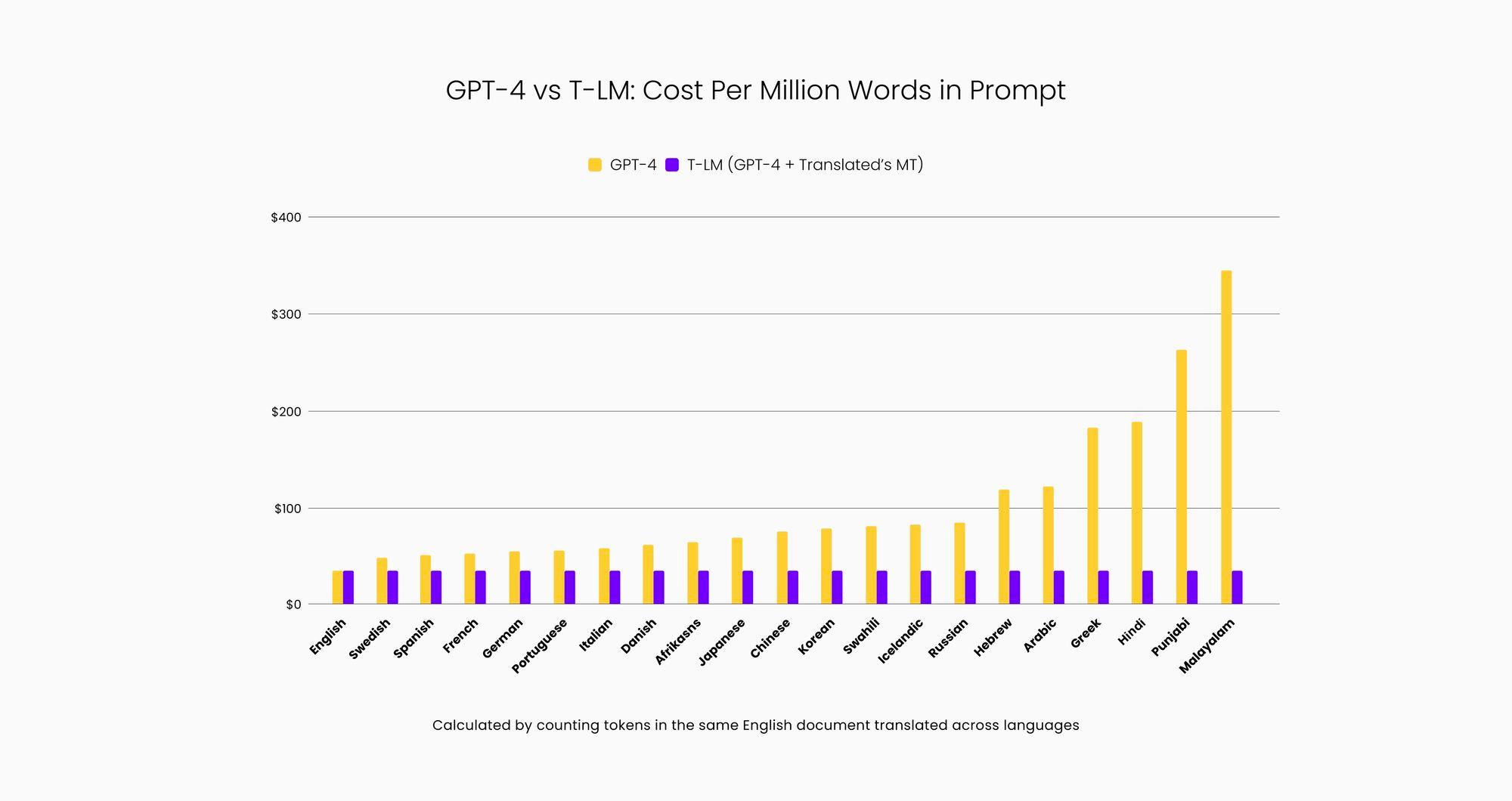
Additionally, using GPT-4 in non-English languages can cost up to 15 times more (see the charts below). Research has shown that speakers of certain languages may be overcharged for language models while obtaining poorer results, indicating that tokenization may play a role in both the cost and effectiveness of language models. This study shows the difference in cost by language family which can be significantly higher than English.
Independent researchers point out how the same prompt varies across languages and that some languages consistently have a higher token count. Languages such as Hindi and Bengali (which together over 800 million people speak) resulted in a median token length of about 5 times that of English. The ratio is 9 times that of English for Armenian and over 10 times that of English for Burmese. In other words, to express the same sentiment, some languages require up to 10 times more tokens.
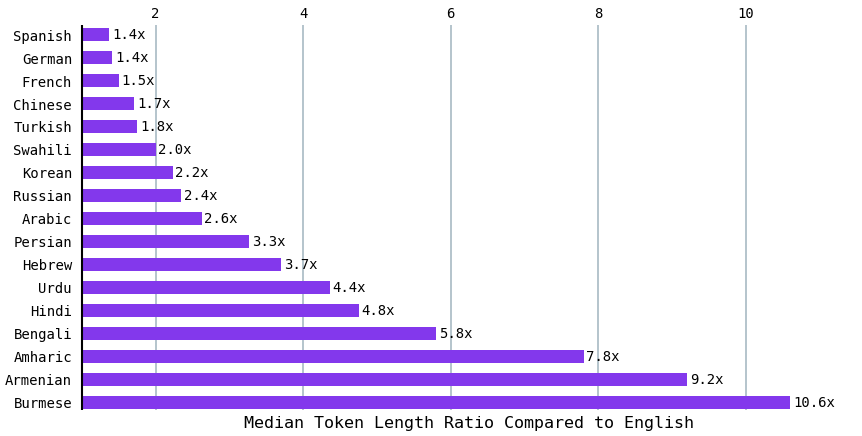
Source: All languages are NOT created (tokenized) equal
Implications of tokenization language disparity
Overall, requiring more tokens (to tokenize the same message in a different language) means:
- Non-English users are limited in how much information they can put in the prompt (because the context window is fixed).
- It is more costly as generally more tokens are needed for equivalent prompts.
- It is slower and takes longer to run and often results in more fabrication and other errors.
OpenAI’s models are increasingly being used in countries where English is not the dominant language. According to SimilarWeb.com, the United States only accounted for 10% of the traffic sent to ChatGPT in Jan-March 2023. India, Japan, Indonesia, and France all have large user populations that are almost as large as the US user base.
Translated's T-LM service integrates the company’s award-winning adaptive machine translation (ModernMT) with GPT-4 to bring advanced generative AI capabilities to every business in the languages spoken by 95% of the world's population. This approach also lowers the cost of using GPT-4 in languages other than English, since the pricing model is based on text segmentation (tokenization) that is optimized for English. By ensuring that all prompts submitted to GPT-4 are in English the billing will be equivalent to the more favorable and generally lower-cost English tokenization. T-LM, instead, will always use the number of tokens in English for billing.
The Adaptive ModernMT technology, unlike most other MT technology available today can learn and improve dynamically and continuously with ongoing corrective feedback daily. Thus, users who work with T-LM can drive continuous improvements in output produced from GPT-4 by providing corrective feedback on the translations produced by T-LM. This is something that is not possible with the most commonly used static MT systems where users would be confined and limited to generic system performance.
T-LM addresses the performance disparity experienced by non-English users by translating the initial prompt from the source language to English and then back to the user's language using a specialized model that has been optimized for the linguistic characteristics typically used in prompts.
T-LM combines GPT-4 with ModernMT, an adaptive machine translation engine, to offer GPT-4 near English-level performance in 200 languages. .
- T-LM works by translating non-English prompts into English, executing them using GPT-4, and translating the output back to the original language, all using the ModernMT adaptive machine translation.
- T-LM is available to enterprises via an API and to consumers through a ChatGPT plugin.
The result is a more uniform language model performance capability across many languages and enhanced GPT-4 performance in non-English languages.
- Customers can optionally use their existing ModernMT keys to employ adaptive models within GPT-4.
- An indirect benefit of T-LM is that it has cost up to 15x lower than GPT-4, thanks to a reduced number of tokens billed. GPT-4 counts significantly more tokens in non-English languages. T-LM, instead, will always use the number of tokens in English for billing
Therefore, Translated's integration with OpenAI enhances GPT-4's performance in non-English languages by combining GPT-4 with the ModernMT adaptive machine translation, resulting in a more uniform language model capability across languages and lower costs.
Use cases for T-LM include assisting global content creation teams in a broad range of international commerce-related initiatives, allowing companies from Indonesia, Africa, and various parts of India to make their products visible in online eCommerce platforms to US and EU customers, providing better multilingual customer support, making global user-generated content visible and understandable in the customer’s language.
T-LM can be used in many text analysis tasks needed in business settings, e.g., breaking down and explaining complicated topics, outlining blog posts, sentiment analysis, personalized responses to customers, summarization, creating email sales campaign material, or suggesting answers to customer agents.
T-LM works together with GPT to create a wide range of written content or augment existing content to give it a different intonation, by softening or professionalizing the language, to improve content creation and transformation automation while providing a fast and engaging user experience. This is now possible to do in 200 languages that ModernMT supports.
There are many ways GPT-4 can produce ‘draft’ text that meets the length and style desired, which can then be reviewed by the user,” Gartner said in a report on how to use GPT-4. “Specific uses include drafts of marketing descriptions, letters of recommendation, essays, manuals or instructions, training guides, social media or news posts.”
T-LM will allow students around the world to access knowledge content and use GPT-4 as a research assistant and access a much larger pool of information. In education, GPT-4 can be used to create personalized learning experiences, as a tutor would. And, in healthcare, chatbots and applications can provide simple language descriptions of medical information and treatment recommendations.
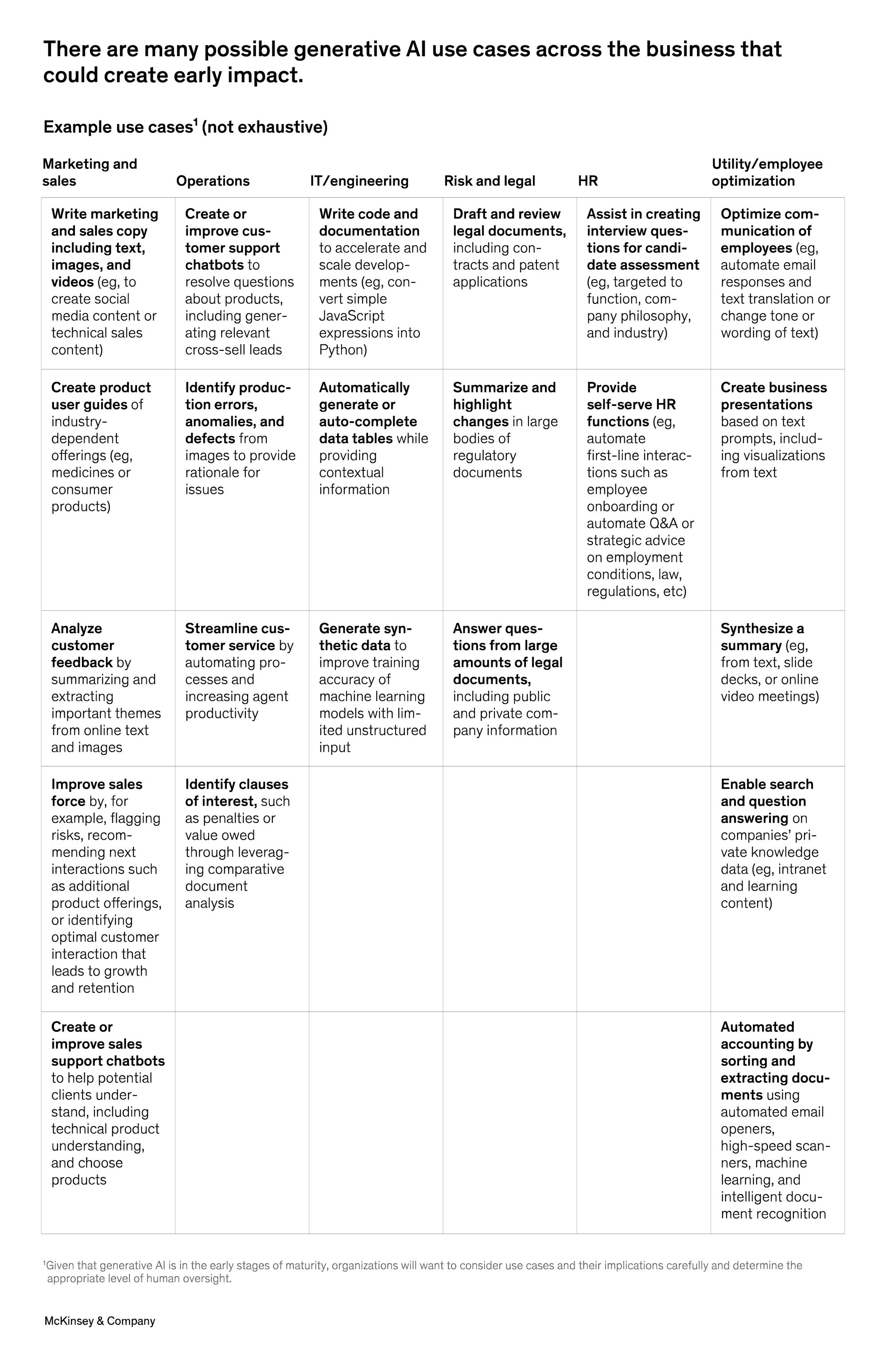
T-LM will enhance the ability of large and SME businesses to engage in new international business by assisting in basic communication, and understanding, and providing more complete documentation on business proposals using the strengths of both GPT-4 and T-LM working together.
T-LM is available now through API. More information on the service can be found at translatedlabs.com/gpt.
ModernMT is a product by Translated.