Comparing MT System Performance
The advantages of a dynamic adaptive MT system are clarified in this post. Most static MT systems need significant upfront investment to enable adaptation. ModernMT has a natural advantage since it is so easily adapted to customer domain and data.

Machine Translation (MT) system evaluation is necessary for enterprises considering increasing the use of automated translation to meet the increasing information and communication needs to engage the global customer. Managers need to understand which MT system is best for their specific use case and language combination, and which MT system will improve the fastest with their data and with the least effort to perform best for the intended use case.
What is the best MT system for my specific use case, and this language combination?
The comparative evaluation of the quality performance of MT systems has been problematic and often misleading because the typical research approach has been to assume that all MT systems work in the same way.
Thus, comparisons by “independent” third parties are generally made at the lowest common denominator level i.e. the static or baseline version of the system. Focusing on the static baseline makes it easier for a researcher to line up and rank different systems but penalizes highly responsive MT systems that are designed and able to immediately respond to the user's focus and requirements, and perform system optimization around user content.
Which MT system is going to improve the fastest with my unique data and require the least amount of effort to get the best performance for my intended use case?
Ideally, a meaningful evaluation would test a model on its potential capabilities with new and unseen data as it is expected that a model should do well on data it has been trained on and knows.
However, many third-party evaluations use generic test data that is scoured from the web and slightly modified. Thus, data leakage is always possible as shown in the center diagram below.
Issues like data leakage and sampling bias can cause AI to give faulty predictions or produce misleading rankings. Since there is no reliable way to exclude test data contained in the training data this problem is not easily solved. Data leakage will cause overly optimistic results (high scores) that will not be validated or seen in product use.

This issue is also a challenge when comparing LLM models especially since much of what LLMs are tested on is data that these systems have already seen and trained on. Some key examples of the problems that data leakage causes in machine translation evaluations include:
- Overly optimistic performance estimates: because the model has already seen some of the test data during training. This gives a false impression of how well the model will perform on real, unseen data.
- Poor real-world performance: Models that suffer from data leakage often fail to achieve anywhere near the same level of performance when deployed on real-world data. The high scores do not translate to the real world.
- Misleading comparisons between models: If some models evaluated on a dataset have data leakage while others do not, it prevents fair comparisons and identifying the best approaches. The leaky models will seem superior but not legitimately so.
In addition, the evaluation and ranking of MT systems done by third parties is typically done using an undisclosed and confidential "test data" set that attempts to cover a broad range of generic subject matter. This approach may be useful for users who intend to use the MT system as a generic, one-size-fits-all tool but is less useful for enterprise users who want to understand how different MT systems might perform on their subject domain and content in different use cases.
Rankings on generic test data are often not likely to be useful for predicting actual performance in the enterprise domain. If the test data is not transparent how can an enterprise buyer be confident that the rankings are valid for their use cases? These often irrelevant scores are used to select an MT system for production work and thus are often sub-optimal.
Unfortunately, enterprises looking for the ideal MT solution have been limited to third-party rankings that focus primarily on comparing generic (static) versions of public MT systems, using undisclosed, confidential test data sets that are irrelevant or unrelated to enterprise subject matter.
With the proliferation of MT systems in the market, translation buyers are often bewildered by the range of MT system options and thus resort to using these rankings to make MT system selections without understanding the limitations of the evaluation and ranking process.
What is the value of scores that provide no insight or detail on what the scores and rankings are based on? Best practices suggest that users have visibility on what data is used to calculate the score for it to be meaningful or relevant.
Thus, Translated recently undertook some MT comparison research to answer the following questions:
- What is the quality performance of an easily tuned and agile adaptive MT system compared to generic MT systems that require special adaptation efforts to accommodate and tune to typical enterprise content?
- Can a comparative analysis be done using public-domain enterprise data so that a realistic enterprise case can be evaluated, and so that others can replicate, reproduce, and verify the results?
- Can this evaluation be done transparently, by making test scripts publicly available so other interested parties can replicate and reproduce the results?
- Additionally, can the evaluation process be easily modified so that comparative performance on other data sets can also be tested?
- Can we provide a better, more accurate comparison of ModernMT's out-of-the-box capabilities against the major MT alternatives available in the market?
This evaluation further validates and reinforces what Gartner, IDC, and Common Sense Advisory have already said about ModernMT being a leader in enterprise MT. This evaluation provides a deeper technical foundation to illustrate ModernMT's responsiveness and ability to quickly adapt to enterprise subject matter and content.
Evaluation Methodology Overview
Translated SRL commissioned Achim Ruopp of Polyglot Technology LLC and asked him to find viable evaluation data and establish an easily reproducible process that could be used to periodically update the evaluation and/or enable others to replicate, reproduce, or otherwise modify the evaluation. He chose the data and developed the procedural outline for the evaluation. This is a typical enterprise use case where MT performance on specialized corporate domain material needs to be understood before deployment in a production setting. It is understood that some of the systems can potentially be further customized with specialized training efforts but this analysis provides a perspective when no effort is made on any of the systems under review.
The process followed by Achim Ruopp in his analysis is shown below:
- Identify evaluation data and extract the available data for the languages that were of primary interest and that had approximately the same volume of data. The 3D Design, Engineering, and Construction software company Autodesk provides high-quality software UI and documentation translations created via post-editing machine translations.
- US English → German,
- US English → Italian,
- US English → Spanish,
- US English → Brazilian Portuguese, and
- US English → Simplified Chinese
- Clean and prepare data into two data sets:
- 1) ~10,000 segments of TM data for each language pair and,
- 2) a Test Set with 1,000 segments that had no overlap with the TM data
- The evaluation aimed to measure the accuracy and speed of the out-of-the-box adaptation of ModernMT to the IT domain and contrast this with generic translations from four major online MT services (Amazon Translate, DeepL, Google Translate, and Microsoft Translator). This is representative of many translation projects in enterprise settings. A zero-shot output score for GPT-4 was also added to show how the leading LLM scores against leading NMT solutions. Thus the “Test Set” was processed and run through all these systems and three versions of ModernMT (Static baseline, Adaptive, and Adaptive with dynamic access to reference TM.) Please note that many “independent evaluations” that compare multiple MT systems focus ONLY on the static version of ModernMT which in reality would rarely happen.
- The MT output was scored using three widely used MT output quality indicators that are based on a reference Test Set. These include:
- COMET – A measure of semantic similarity that achieves state-of-the-art levels of correlation with human judgment and is the most commonly used metric in current expert evaluations.
- SacreBLEU – A measure of syntactic similarity that is possibly the most popular metric used in MT evaluation, despite many shortcomings, that compares the token-based similarity of the MT output with the reference segment and averages it over the whole corpus.
- TER – A measure of syntactic similarity that measures the number of edits (insertions, deletions, shifts, and substitutions) required to transform a machine translation into a reference translation. This is a measurement that is popular in the localization industry.
- The results and scores produced are presented in detail in this report in a series of charts with some limited commentary. The summary is shown below. The objective was to understand how ModernMT performs relative to the other alternatives and provide a more accurate out-of-the-box picture, thus the focus of this evaluation remains on how systems perform without any training or customization effort. It is representative of the results if the user were to make virtually no effort beyond pointing to a translation memory.
Summary Results
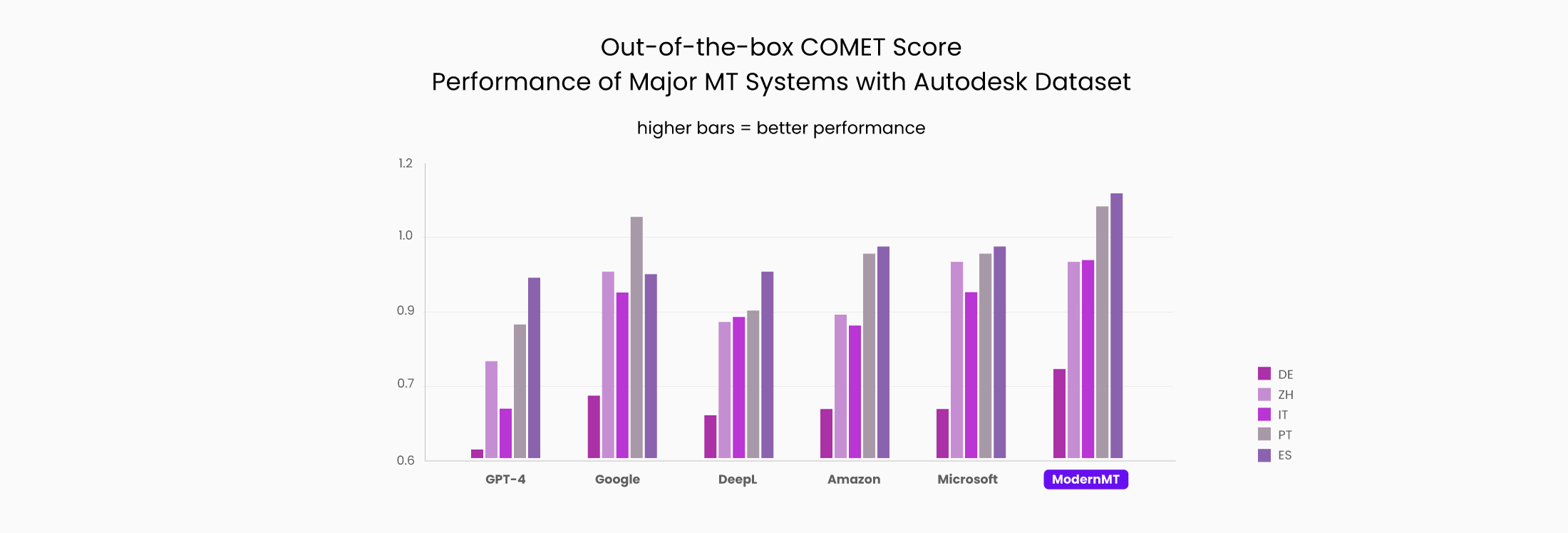
- This is the first proper evaluation and comparison of ModernMT's out-of-the-box adaptive MT model (with access to a small translation memory, but not trained) against leading generic (or static) public MT systems.
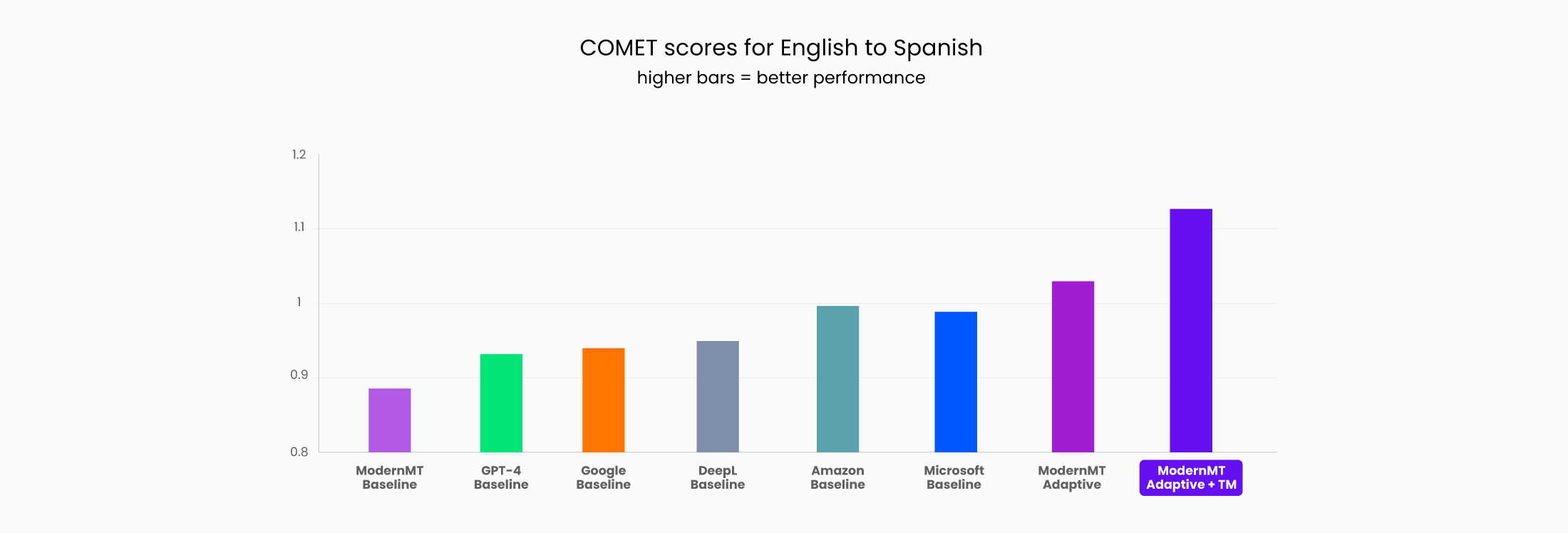
- The comparison shows that ModernMT outperforms generic public MT systems using data from an Autodesk public dataset, where translation performance was measured for translation from US English to German, Italian, Spanish, Brazilian Portuguese, and Simplified Chinese using COMET, SacreBLEU, and TER scoring.
- ModernMT achieves these results without any overt training effort, simply by dynamically using and referencing relevant translation memory (TM) when available.
- A state-of-the-art LLM (GPT-4) failed to outperform the production NMT systems in most of the tests in this evaluation.
- The evaluation and comparison tools and research data are in the public domain. Interested observers can replicate the research with their own data.
Why is MT evaluation so difficult?
Language is one of the most nuanced, elaborate, and sophisticated mediums used by humans to communicate, share, and gather knowledge. It is filled with unwritten and unspoken context, emotion, and intention that is not easily contained in the data used to train machines on how to understand and translate human language. Thus, machines can only approach language at a literal textual string level and will likely always struggle with finesse, insinuation, and contextual subtleties that require world knowledge and common sense. Machines have neither.
Thus, while it is difficult to do this kind of evaluation with absolute certainty, it is still useful to get a general idea. MT systems will tend to do well on material that is exactly like the material they train on and function almost like translation memory in this case. Both MT system developers and enterprise users need to have some sense of what system might perform best for their purposes.
It is common practice to test MT system performance on material it has not already memorized to get a sense of what system performance will be in real-life situations. Thus quick and dirty quality evaluations provided by BLEU, COMET, and TER can be useful even though they are never as good as expert, objective human assessments. These metrics are used because human assessment is expensive and slow and also difficult to do consistently and objectively over time.

To get an accurate sense of how an MT system might perform on new and unseen data it is worth considering how these factors could undermine any absolute indication of any one system being “better” or “worse” than any other.
- Language translation for any single sentence does not have a single correct answer. Many translations could be useful and adequate for the purpose at hand.
- It is usually recommended that a varied but representative set of 1,000 to 2,000 segments/sentences be used in an evaluation. Since MT systems will be compared and scored against this “gold standard” the Test Set should be professionally done. This can cost $1,500 to $2,500 per language. So, 20 languages can cost $50,000 just to create the Test Set. This cost often results in MT use to reduce costs which builds in a bias for the MT system (typically Google) used to produce this data.
- There is no definitive way to ensure that there is no overlap between the training data and the test data so data leakage can often undermine the accuracy of the results.
- It is easier to use generic tests but the most useful performance indicators in production settings will always be with carefully constructed test sentences of actual enterprise content (that are not contained in the training set).
Automated quality evaluation metrics like COMET are indeed useful but the experts in the community now realize that these scores have to be used together with competent human assessments to get an accurate picture of the relative quality of different MT systems. Using automated scores alone is not advised.

What matters most?
This post explores some broader business issues that should also be considered when considering MT quality.
While much attention is given to comparative rankings of different MT systems, one should ask how useful this is in understanding how any particular MT system will perform on any enterprise-specific use case. Scores on generic test sets do not accurately predict how a system will perform on enterprise content in a highly automated production setting.
The rate at which an MT system improves for specific enterprise content is possibly the most important criterion for MT system selection.
Ideally, it should be daily or at least weekly.
So instead of asking what COMET score System A has on its EN > FR system? It is important to ask other questions that are more likely to ensure successful outcomes. The answers to the following questions will likely lead to much better MT system selections.
- How quickly will this system adapt to my unique customer content?
- How much data will I need to provide to see it perform better on my content and use case?
- How easy is it to integrate the system with my production environment?
- How easy or difficult is it to set up a continuously improving system that continues to improve and learn from ongoing corrective feedback?
- How easy or difficult is it to manage and maintain my optimized systems on an ongoing basis?
- Can I automate the ongoing MT model improvement process?
- Ongoing improvements are driven both by technology enhancements and by expert human feedback, are both these available from this vendor?
Please follow this link for a detailed report on this evaluation and more detailed analysis and commentary on understanding MT evaluation from a more practical and business-success-focused perspective.