ModernMT Introduces Adaptive Quality Estimation (MTQE)
As MT quality improves, MT use expands to publishing millions of words monthly to improve global customer experience. MTQE can quickly identify potential problems to focus MTPE only on the most problematic sections and quickly publish large volumes of global CX-enhancing content safely.

Historically, the path to achieving quality in professional language translation work is to involve multiple humans in the creation and validation of every translated segment. This multi-human translation production process is known as TEP or Translate > Edit > Proof. The way to guarantee the best translation quality will be produced has always been to provide a quality review by a second and sometimes a third person. When this process works well it produces “good quality” translation, but this approach also has serious limitations:
1) it is an ad-hoc process with constantly changing humans that can result in the same mistakes happening again, and,
2) it is a time-consuming, miscommunication-prone, and costly process that is difficult to scale as volumes increase.
The TEP model has been the foundation for much of the professional translation work done over the last 20 years and is still the production model used for much of the translation work managed by localization groups. While this is a historical fact, the landscape for professional business translation has been changing in two primary ways:
1) The volumes of content that need to be translated to be successful in international business settings are continually increasing,
2) An increasing need and use of machine translation and more automation to cope with the ever-increasing demand, and the need for much faster turnaround on translation projects.
One solution to this problem is to increase the use of machine translation and post-edit the output (MTPE or PEMT). This is an attempt to reproduce part of the entirely human TEP process described above with a machine starting the process. This approach has met with limited success, and many LSPs and localization managers struggle to find an optimal MT process due to the following issues:
Uneven or poor machine translation quality: The automation can only be successful when the MT provides a useful and preferably continuously improving first draft submitted for human approval or refinement. MT quality varies by language and few LSPs and localization managers know how to engineer and optimize MT systems to perform optimally for their specific needs. Recent surveys by researchers show that LSPs (and localization managers) still struggle to meet quality expectations and estimate cost and efforts when using MT.
Translator resistance: As MTPE is a machine output-driven process, and typically paid at lower unit rates, many translators are loathe to do this kind of work without assurances that the MT will be of adequate quality to assure fair overall compensation. Low quality MT is much more demanding to correct and thus translators find that their compensation is negatively impacted when they work with low-quality MT. The converse is also true, many translators have found that high-quality adaptive MT work results in higher-than-expected compensation due to the continuous improvement in the MT output and overall system responsiveness.
Lack of standardization: there is currently no standardization in the post-editing process, which can lead to inconsistencies in the quality of the final translation.
Training and experience: Post-editing MT requires a different skill set than traditional translation, and post-editors need to be trained accordingly. The translator versus post-editing task remains a source of friction in an industry that depends heavily on skillful human input, largely due to improper work specification, and compensation-related concerns.
Cost: Post-editing can be expensive, especially for large volumes of text. This can be a significant obstacle for companies that need to translate large amounts of content since it is often assumed that all the MT output must be reviewed and edited.
MT Quality Evaluation vs MT Quality Estimation
But as we move forward and expand the use of machine translation to make ever-increasing volumes of content multilingual, we see the need for two kinds of quality assessment tools that can be useful to any enterprise that seeks to be multilingual at scale.
1) Quality Evaluation estimates provide a quality assessment of multiple versions of an MT system that may be used by the MT system developers to better understand the impact of changing development strategies. Commonly used evaluation metrics include BLEU, COMET, TER, and ChrF which all use a human reference test set (the gold standard) to calculate a quality score of each MT system’s performance and is well understood by the developer. These scores are useful to developers to find optimal strategies in the system development process but unfortunately, these scores are also used by “independent” researchers who seek to sell aggregation software to less informed buyers and localization managers who usually have limited understanding of the scores, the test sets, and the opaque process used to generate the scores. Thus, buyers will often make sub-optimal and naïve choices in MT system selection.
2) Quality Estimation scores, on the other hand, are quality assessments made by the machine without using reference translations or actively requiring humans in the loop. It is, in a sense, an assessment of quality made by a machine itself on how good or bad a machine-translated output segment is. MTQE can serve as a valuable tool for risk management in high-volume translation scenarios where human intervention is limited or impractical due to the volume of translations or speed of delivery. MTQE enables efficiency and minimizes potential risks associated with using raw MT because it directs attention to the most likely problematic translations, and reduces the need to look at all the automated translations.
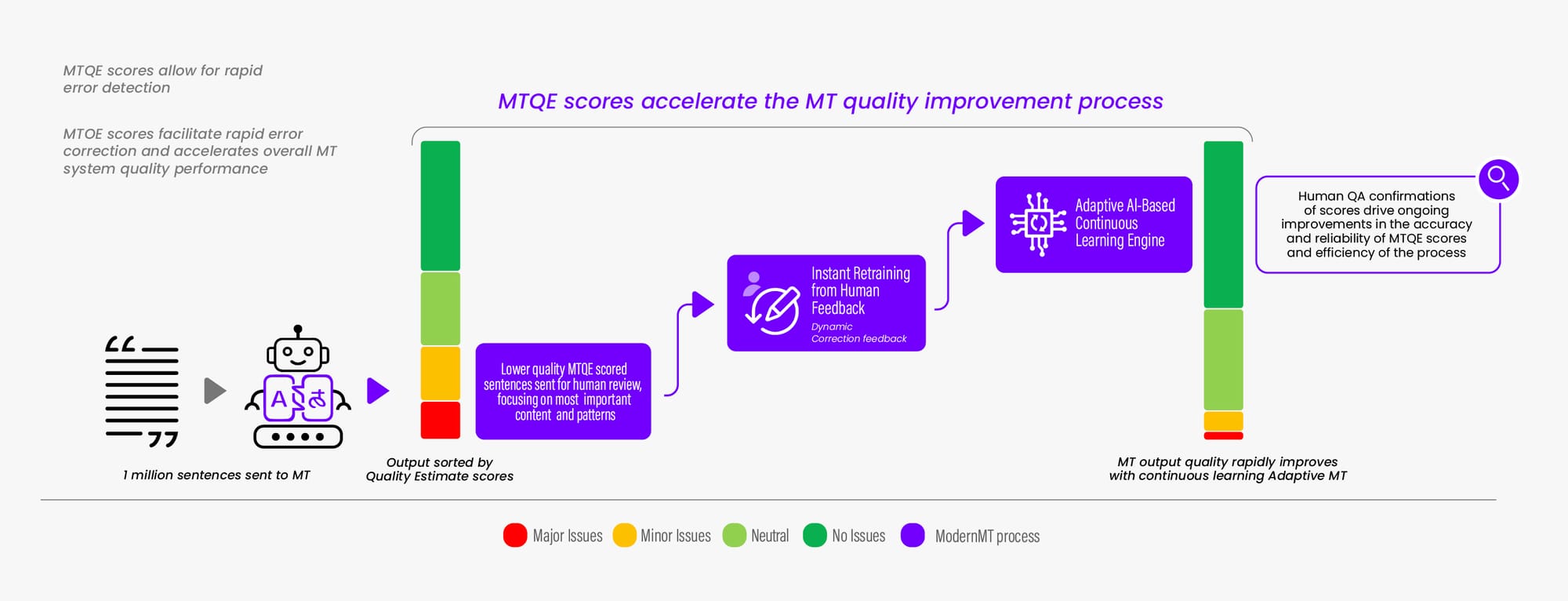
Interest in MTQE has gained momentum as the use of MT has increased, as it allows rapid error detection in large volumes of MT output, thus enabling rapid and focused error correction strategies to be implemented.
Another way to understand MTQE is to more closely examine the difference in training data used in developing an MT engine versus the data used in building a QE model. An MT system is trained on large volumes of source and target sentence pairs or segments or what is generally called translation memory.
An MTQE system is trained on the original MT output and corrected sentence pairs which are also compared to the original source (ground truth) to identify error patterns. The MTQE validation process seeks to confirm that there is a high level of agreement between a machine's quality prediction of machine output and human quality assessment of that same output
Quality estimation is a method for predicting the quality without having to compare it to a human reference set. Quality estimation uses machine learning methods to assign quality scores to machine-translated segments and since it works through machine learning it can be used in dynamic, live situations. Quality estimation can predict quality at various levels of text, including at the level of the word, phrase, sentence, or even document but is used most commonly at a segment level.
What is T-QE?
The current or traditional process used to improve adaptive machine translation quality uses one of two methods:
1) random segments are selected and reviewed by professional translators or,
2) every segment has to be reviewed by a translator to ensure the required quality.
However, as MT content volumes rapidly increase in the enterprise, it becomes more important to make this process more efficient, as these human review methods do not scale easily. It is useful to the production process to rapidly identify those segments that most need human attention, and focus critical corrective feedback primarily on these problem segments to enable the MT system to continually improve and ensure overall improved quality on a large content volume.
The MT Quality Estimator (T-QE) streamlines the system improvement process by providing a quality score for each segment, thus identifying those segments that most need human review, rather than depending only on random segment selection, or requiring that each segment be reviewed.
The basic idea is to enable the improvement process to be more efficient by immediately focusing 80% of the human corrective effort on the 20% lowest-scoring segments. Essentially, the 80:20 rule is a principle that helps individuals and companies prioritize their efforts to achieve maximum impact with the least amount of work. This approach allows overall MT quality, especially in very large-scale or real-time deployments, to improve rapidly.
The MT Quality Estimator assists in solving this challenge by providing an MT quality score for each translated segment, directly within Matecat or via an API.
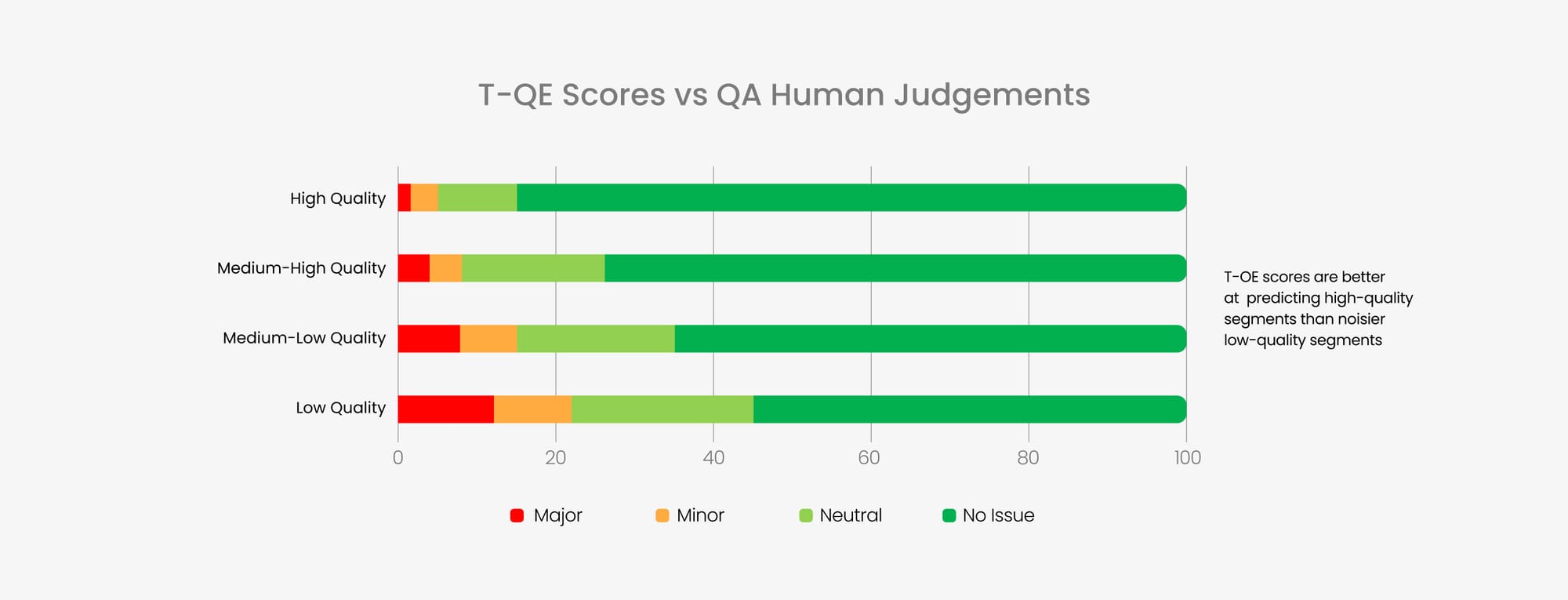
The MT Quality Estimator at Translated was validated by taking many samples (billions of segments) of different types of content of varying source quality and comparing the correlation between the T-QE scores and human quality assessments.
The initial tests conducted by the ModernMT team suggest that the T-QE scores are more accurate predictors on high-quality segments but it was noted that lower-quality segments contained more UGC, had longer sentences, and were in general noisier.
The Key Benefits of MT Quality Estimation
Human review at a global content scale is unthinkable, costly, and probably a physical impossibility because of the ever-increasing volumes. As the use of MT expands across the enterprise to drive international business momentum and as more automated technology is used, MTQE offers enterprises a way to identify and focus on the content that needs the least, and the most attention, before it is released into the wild.
MTQE is an effective means to manage risk when an enterprise wishes to go multilingual at scale. Quality estimation can predict the quality of a given machine translation, allowing for corrections to be made before the final translation is published. MTQE identifies high-quality MT output that does not require human post-editing and thus makes it easier to focus attention on the lower-quality content, allowing for faster turnaround times and increased efficiency.
When a million sentences of customer-relevant content need to be published using MT, MTQE is a means to identify the ~10,000 sentences that most need human corrective attention to ensure that global customers receive acceptable quality across the board.
This informed identification of problems that need to be submitted for human attention is essential to allow for a more efficient allocation of resources and improved productivity. This process enables much more content to be released to global customers without risking brand reputation, and ensuring that desired quality levels are achieved.
When MTQE is paired and combined with a highly responsive MT system, like ModernMT, it can accelerate the rate at which large volumes of customer-relevant content can be released and published for a growing global customer base.
MTQE provides great value in identifying the content that needs more attention and also identifying the content that can be used in its raw MT form, thus speeding up the rate at which new content can be shared with a global customer base.
“We believe that localization value comes from offering the right balance between quality and velocity,” says Conchita Laguardia, Senior Technical Program Manager at Citrix, and “the main benefit QE gives is the ability to release content faster and more often.”
Other ways that MTQE ratings can also be used include:
- Informing an end user or a localization manager about the overall estimated quality of translated content at a corpus level,
- Identifying different kinds of matches in translation memory, e.g., an In-Context Exact (ICE) match is a type of translation match that guarantees a high level of appropriateness by the match having been previously translated in the same context. It is an exact match that occurs in exactly the same context, that is, the same location in a paragraph, which is better than a 100% match and better than fuzzy matches of 80% or less. These different types of TM matches can be processed in differently optimized localization workflows to maximize efficiency and productivity and are useful even in traditional localization work.
- Deciding if a translation is ready for publishing or if it requires human post-editing,
- Highlighting problematic content that needs to be revised and changed.
The pairing of content with lower MTQE scores into a workflow that also links into a responsive, continuously learning, adaptive MT system like ModernMT, makes for a powerful translation engine that can handle making large volumes of content multilingual without compromising overall translation quality.
Effective MTQE systems allow the enterprise to produce higher quality fast translations at low cost and safely increase the use of “raw MT”.
The MT Quality Estimator at Translated has been trained on a dataset comprising over 5 billion sentences from parallel corpora (source, MT output, and corrected output) and professional translations in various fields and languages. The AI identifies and learns the error correction patterns by training on these billions of sentences, and provides a reliable prediction of which segments are most likely to need no correction, thus efficiently directing translators to those low-scoring segments that are most likely to need correction. MTQE can be combined with ModernMT, to automatically provide an overall MT quality score for a custom adaptive model, as well as a quality score for MT suggestions within Matecat.
When combined with a highly responsive MT system like ModernMT, it is also possible to improve the overall output quality of a custom MT model by focusing human review only on those sentences that fall below a certain quality score.
Salvo Giammarresi, head of localization of Airbnb, a company that has been beta-testing the service, says:
“Thanks to T-QE, Airbnb can systematically supervise the quality of content generated by users, which is processed through our custom MT models. This allows us to actively solicit professional translator reviews for critical content within crucial areas. This is vital to ensure that we are providing our clients with superior quality translations where it truly matters”.
Ongoing Evolution: Adaptive Quality Estimation
The ability to quickly identify errors and focus on reducing the size of the overall data set that needs to receive corrective feedback is an important goal of the MTQE technology. Focus on identifying the most problematic segments and correct them quickly. Any innovation that reduces the amount of data that needs to be reviewed to improve a larger corpus is valuable.
Thus, while the original MTQE error identification process uses the most common error patterns learned from the 5 billion-sentence generic dataset, the ModernMT team is also exploring the benefits of applying the adaptive approach to MTQE segment prediction.
The impact of this innovation is significant. The following hypothetical example illustrates the potential impact and reflects the experience of early testing. (This will, of course, vary depending on the dataset and data volume.)
For example, if an initial review of 40% of the sentences with the lowest MTQE score using the generic MTQE model identifies 60% of the major problems in a corpus, using the adaptive model with customer data can result in the identification of 90% of the major problems in a corpus by focusing only on the 20% with the lowest MTQE score using the adaptive MTQE model.
This ability to improve the overall quality of the published corpus by looking at less data, dramatically increases the efficiency of the MTQE-based improvement process. This is technological leverage that benefits large-scale translation production.
T-QE is primarily designed and intended for high-volume enterprise users but is also available for translators in MateCat or by API for enterprises. Please contact info@modernmt.com for more information.
ModernMT is a product by Translated.