The Evolution of AI Translation Technology
A summary of the history of innovation in the production use of leading-edge translation technology at Translated with a perspective on the emerging future in the application of LLMs in production translation

Translated is a pioneer in using MT in professional translation settings at a production scale. The company has a long history of innovation in the effective use of MT technology (an early form of AI) in production settings. It has deployed MT extensively across much of its professional translation workload for over 15 years and has acquired considerable expertise in doing this efficiently and reliably.
Machine Translation
IS
Artificial Intelligence
One of the main drivers behind language AI has been the ever-increasing content volumes needed in global enterprise settings to deliver exceptional global customer experience. The rationale behind the use of language AI in the translation context has always been to amplify the ability of stakeholders to produce higher volumes of multilingual content more efficiently and at increasingly higher quality levels.
Consequently, we are witnessing a progressive human-machine partnership where an increasing portion of the production workload is being transferred to machines as the technology advances.
Research analysts have pointed out that even as recently as 2022-23 LSPs and localization departments have struggled with using generic (static) MT systems in enterprises for the following reasons:
- Inability to produce MT output at the required quality levels. Most often due to a lack of training data needed to see meaningful improvement.
- Inability to properly estimate the effort and cost of deploying MT in production.
- The ever-changing needs and requirements of different projects with static MT that cannot adapt easily to new requirements create a mismatch of skills, data, and competencies.
The Adaptive MT Innovation
In contrast to much of the industry, Translated was the first mover in the production use of adaptive MT since the Statistical MT era. The adaptive MT approach is an agile and highly responsive way to deploy MT in enterprise settings as it is particularly well-suited to rapidly changing enterprise use case scenarios.
From the earliest days, ModernMT was designed to be a useful assistant to professional translators to reduce the tedium of the typical post-editing (MTPE) work process. This focus on building a productive and symbiotic human-machine relationship has resulted in a long-term trend of continued improvement and efficiency.
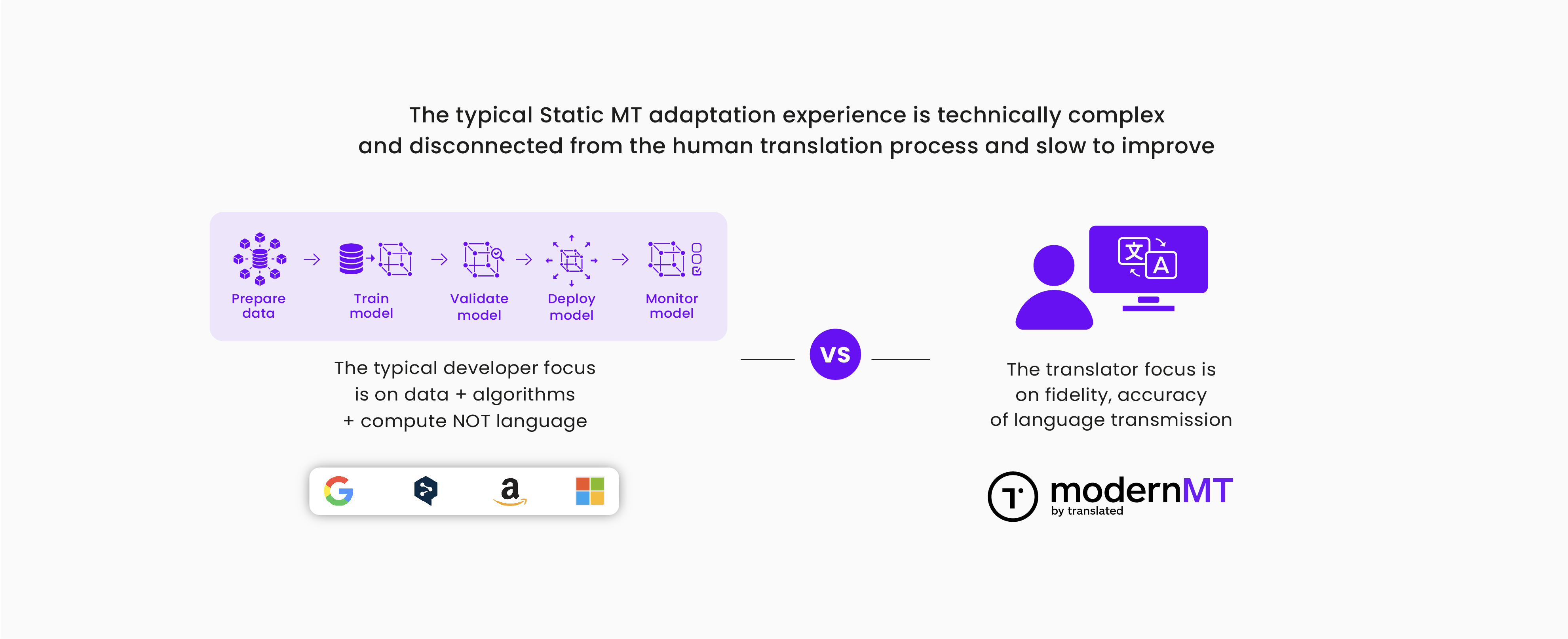
ModernMT is an adaptive MT technology solution designed from the ground up to enable and encourage immediate and continuous adaptation to changing business needs. It is designed to support and enhance the professional translator's work process and increase translation leverage and productivity beyond what translation memory alone can. It is a continuous learning system that improves with ongoing corrective feedback. This is the fundamental difference between an adaptive MT solution like ModernMT and static generic MT systems.
The ModernMT approach to MT model adaptation is to bring the encoding and decoding phases of model deployment much closer together, allowing dynamic and active human-in-the-loop corrective feedback, which is not so different from the in-context corrections and prompt modifications we are seeing being used with large language models today.
It is now common knowledge that machine learning-based AI systems are only as good as the data they use. One of the keys to long-term success with MT is to build a virtuous data collection system that refines MT performance and ensures continuous improvement. This high-value data collection effort has been underway at Translated for over 15 years and is a primary reason why ModernMT outperforms competitive alternatives.
This is also a reason why it makes sense to channel translation-related work through a single vendor so that an end-to-end monitoring system can be built and enhanced over time. This is much more challenging to implement and deploy in multi-vendor scenarios.
The existence of such a system encourages more widespread adoption of automated translation and enables the enterprise to become efficiently multilingual at scale. The use of such a technological foundation allows the enterprise to break down the language as a barrier to global business success.
The MT Quality Estimation & Integrated Human-In-The-Loop Innovation
As MT content volumes rapidly increase in the enterprise, it becomes more important to make the quality management process more efficient, as human review methods do not scale easily. It is useful for any multilingual-at-scale initiative to rapidly identify the MT output that most need correction and focus critical corrective feedback primarily on these lower-quality outputs to enable the MT system to continually improve and ensure overall improved quality on a large content volume.
The basic idea is to enable the improvement process to be more efficient by immediately focusing 80% of the human corrective effort on the 20% lowest-scoring segments. Essentially, the 80:20 rule is a principle that helps individuals and companies prioritize their efforts to achieve maximum impact with the least amount of work. This leveraged approach allows overall MT quality, especially in very large-scale or real-time deployments, to improve rapidly.
Human review at a global content scale is unthinkable, costly, and probably a physical impossibility because of the ever-increasing volumes. As the use of MT expands across the enterprise to drive international business momentum and as more automated language technology is used, MTQE technology offers enterprises a way to identify and focus on the content that needs the least, and the most human review and attention, before it is released into the wild.
When a million sentences of customer-relevant content need to be published using MT, MTQE is a means to identify the ~10,000 sentences that most need human corrective attention to ensure that global customers receive acceptable quality across the board.
This informed identification of problems that need to be submitted for human attention is essential to allow for a more efficient allocation of resources and improved productivity. This process enables much more content to be published without risking brand reputation and ensuring that desired quality levels are achieved. In summary, MTQE is a useful risk management strategy as volumes climb.
Pairing content with lower MTQE scores into a workflow that connects a responsive, continuously learning adaptive MT system like ModernMT with expert human editors creates a powerful translation engine. This combination allows for handling large volumes of content while maintaining high translation quality.
When a responsive adaptive MT system is integrated with a robust MTQE system and a tightly connected human feedback loop, enterprises can significantly increase the volume of published multilingual content.
The conventional method, involving various vendors with distinct processes, is typically slow and prone to errors. However, this sluggish and inefficient method is frequently employed to enhance the quality of MT output, as shown below.
Rapidly pinpointing errors and concentrating on minimizing the size of the data set requiring corrective feedback is a crucial aim of MTQE technology. The business goal centers on swiftly identifying and rectifying the most problematic segments.
Speed and guaranteed quality at scale are highly valued deliverables. Innovations that decrease the volume of data requiring review and reduce the risk of translation errors are crucial to the business mission.
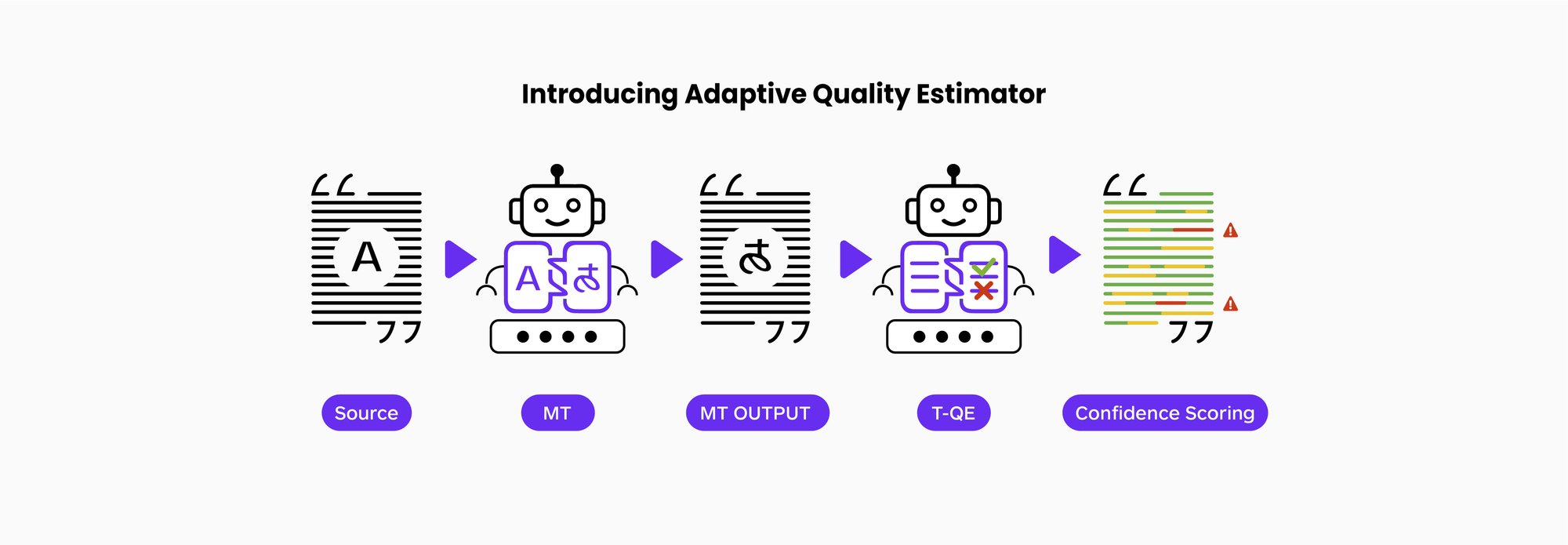
The additional benefit of an adaptive rather than a generic MTQE process further extends the benefit of this technology by reducing the amount of content that needs careful review.
The traditional model of post-editing everything is now outdated.
The new approach entails translating everything and then only revising the most crucial parts to ensure an acceptable level of quality.
For example, if an initial review of 40% of the sentences with the lowest MTQE score using a generic MTQE model identifies 60% of the major problems in a corpus, using the adaptive QE model informed by customer data can result in the identification of 90% of the "major" translation problems in a corpus by focusing only on the 20% lowest scoring MTQE scores using the adaptive MTQE model.
This innovation greatly enhances the overall efficiency. The chart below shows how a process that integrates adaptive MT, MTQE, and focused human-in-the-loop (HITL) work together to build a continuously improving translation production platform.
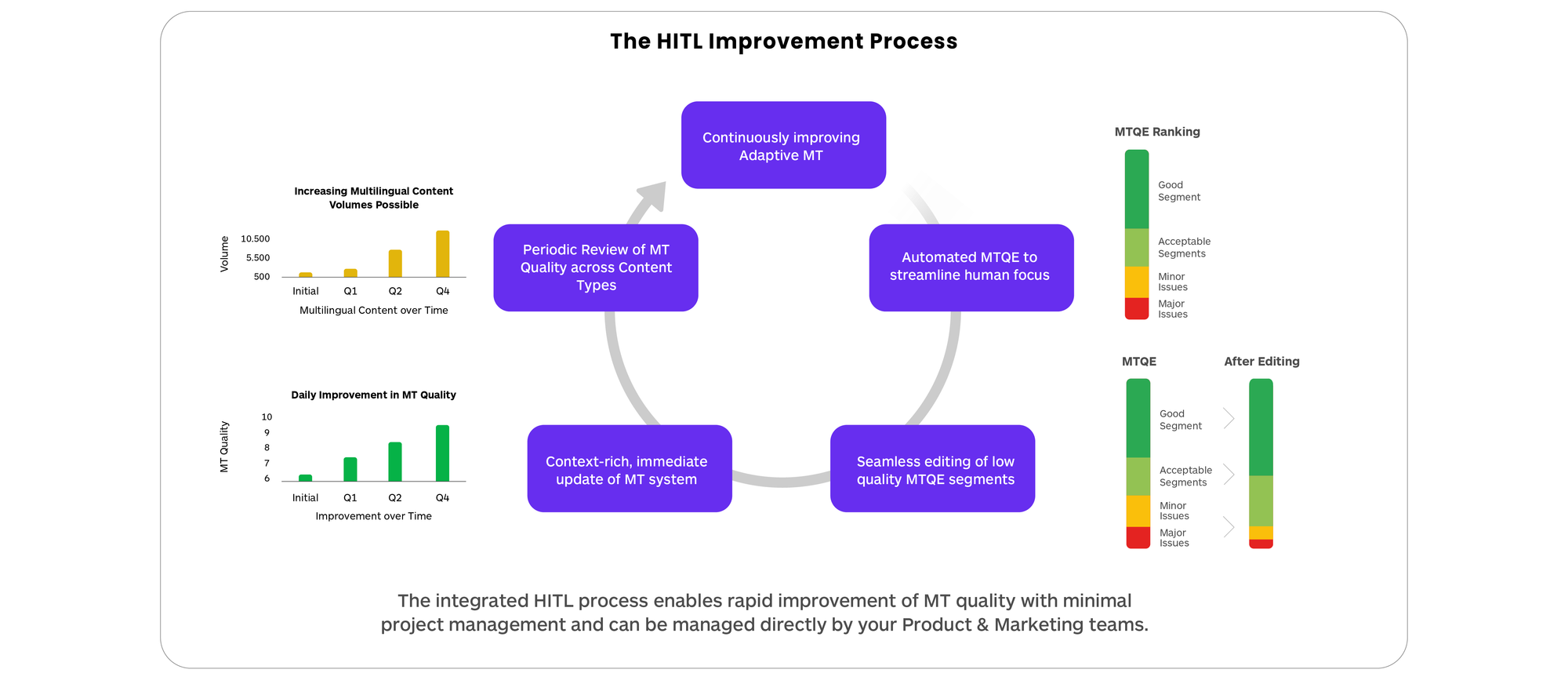
The capability to enhance the overall quality of translation in a large, published corpus by analyzing less data significantly boosts the efficiency and utility of automated translation. An improvement process based on Machine Translation Quality Estimation (MTQE) is a form of technological leverage that advantages extensive translation production.
The Evolving LLM Era and Potential Impact
The emergence of Large Language Models (LLMs) has opened up thrilling new opportunities. However, there is also a significant number of vague and ill-defined claims of "using AI" by individuals with minimal experience in machine learning technologies and algorithms. The disparity between hype and reality is at an all-time high, with much of the excitement not living up to the practical requirements of real business use cases. Beyond concerns of data privacy, copyright, and the potential for misuse by malicious actors, issues of hallucinations and reliability persistently challenge the deployment of LLMs in production environments.
Enterprise users expect their IT infrastructure to consistently deliver reliable and predictable outcomes. However, this level of consistency is not currently easily achievable with LLM output. As the technology evolves, many believe that expert use of LLMs could significantly and positively impact current translation production processes.
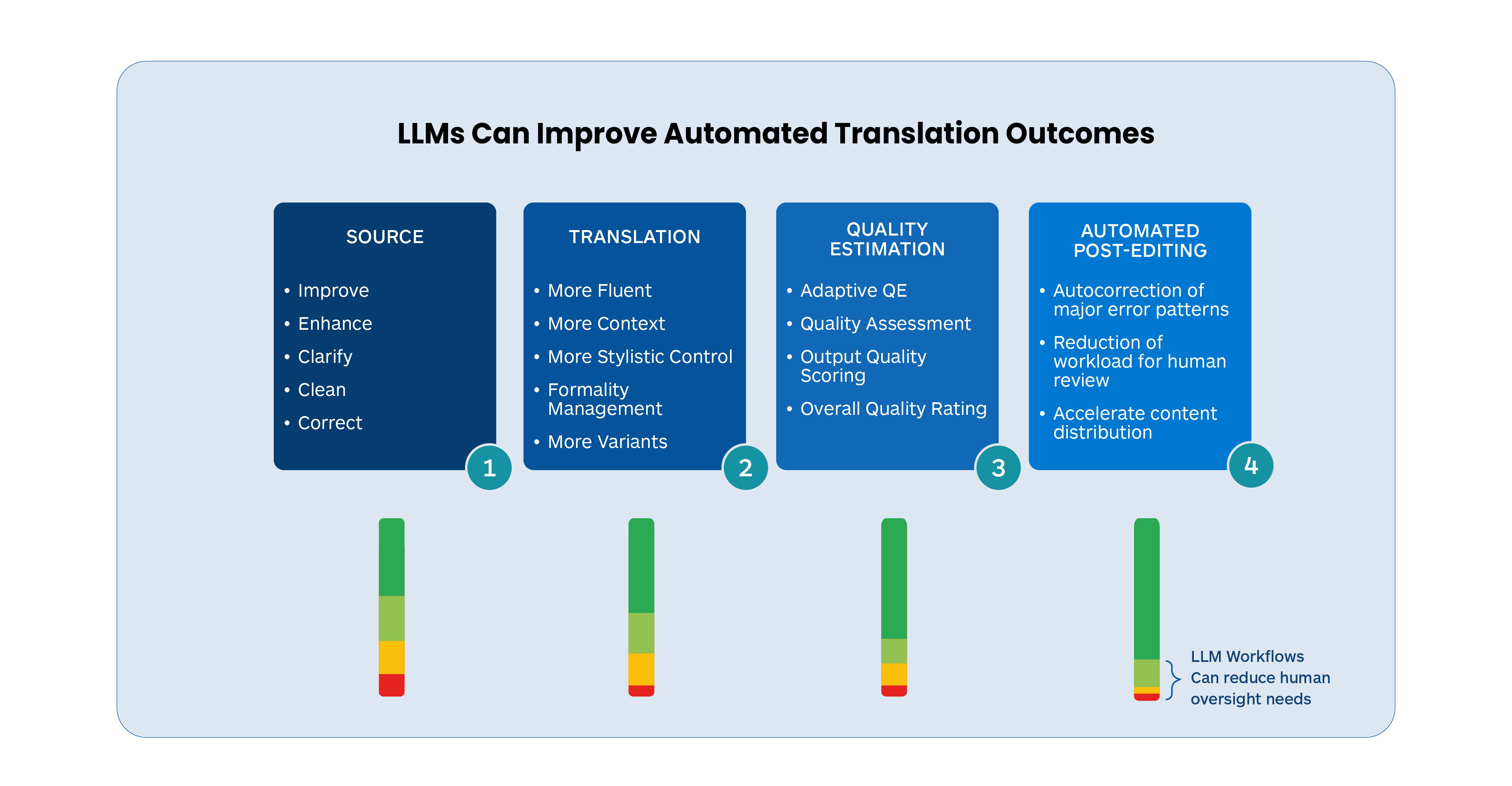
There are several areas in and around the machine translation task where LLMs can add considerable value to the overall language translation process. These include the following:
- LLM translations tend to be more fluent and acquire more contextual information albeit in a smaller set of languages
- Source text can be improved and enhanced before translation to produce better-quality translations
- LLMs can make quality assessments on translated output and identify different types of errors
- LLMs can be trained to take corrective actions on translated output to raise overall quality
- LLM MT is easier to adapt dynamically and can avoid the large re-training that typical static NMT models require
At Translated, we have been carrying out extensive research and development over the past 12 months into these very areas, and the initial results are extremely promising, as outlined in our recent whitepaper.
One strategy with LLM technology employs distinct LLM modules to manage each task category independently. Alternatively, these modules can be combined into a cohesive integrated workflow, enabling users to simply submit their content and obtain an optimal translation. This integrated method encompasses MTQE, along with automated review and post-editing processes.
While managing these tasks separately can potentially offer more control, which can be useful in production enterprise settings, most users prefer a streamlined workflow that focuses on delivering optimal results with minimal effort, with the technology working efficiently behind the scenes.
The chart below shows evidence of our progress with LLMs. MT quality performance is compared across several languages and the chart compares the relative output quality performance of the following systems Google (static), DeepL (static), Translated LLM MT (Lara RAG), GPT-4o (5-shot), and also a ModernMT adapted system.
The Translated system is designed to be used and is optimized for Enterprise Content as the significantly better COMET scores below show.
COMET scores provide a rough estimation of translation quality in active research settings, as shown above, however, these scores are not accurate in an absolute sense and need to be validated by professional human translator assessments whose interpretation of score differences is more useful. Major public neural machine translation (NMT) engines often achieve high scores on public datasets such as Flores, likely because they have been trained or their performance has been optimized on this data.
The following chart shows a more granular Comet score performance comparison by language for Travel industry enterprise content (higher is better). It illustrates how much better system performance can be when expert efforts are made to tune the system to enterprise content.
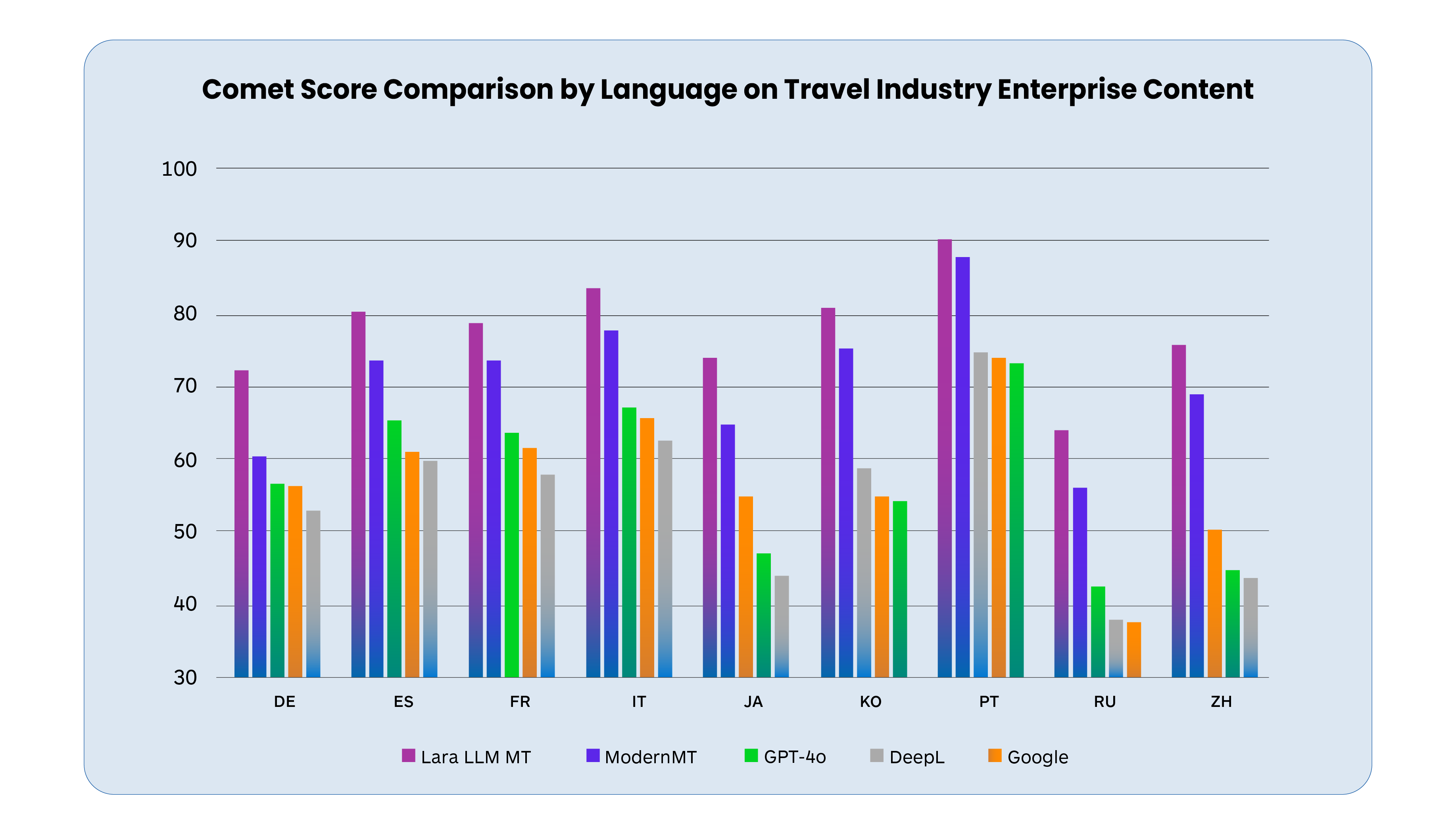
While initial Translated LLM MT results are promising, the outcomes for deployment in enterprise settings require consistency, predictability, and reliability, which we have come to expect with Adaptive NMT. This assured reliability is still evolving with LLM MT but the outlook is generally positive. The following factors need advancement for further momentum to build:
- Adaptability: Today's adaptive NMT models can be instantly tuned (ModernMT) to meet unique domain and customer-specific needs. LLM models perform well in generic performance comparisons but lag in domain-specific use cases.
- Complexity of Adaptation: The fine-tuning process is more complex, less consistent, and less predictable than it is with NMT models. Loading TM chunks into prompts has minimal or unpredictable impact on quality, and more robust and consistent approaches are needed.
- Language Coverage & Training Data Scarcity: Translation-focused Transformer models seem to learn best from high-quality bilingual text. In the case of LLM MT, this data exists only for ~25 high-resource languages. NMT has also struggled with low-resource languages but is now available in 200+ languages.
- GPU Shortage & Scarcity: This slows down research that could potentially produce more efficient, smaller footprint models.
- Data Privacy & Security: Issues remain unresolved or muddy when using the public LLMs.
- Integration and Deployment Ease: LLM latency prohibits it from being deployed in high-volume translation production workflows. The need for human oversight also limits the use of LLM MT in autonomous workflows, thus it is currently best suited for lower volume, human-in-the-loop (HITL), refinement-focused kinds of use scenarios.
While costs are artificially low for many proprietary LLMs and dropping they are subsidized, and many investors are now demanding that LLM initiatives be financially self-sufficient. Investors are now aware that developing large foundation models is capital intensive and returns are still meager, thus there is upward price pressure.
LLM-based machine translation needs to be secure, reliable, consistent, predictable, and efficient for it to be a serious contender to replace state-of-the-art (SOTA) NMT models. This transition is underway but will need more time to evolve and mature.
Thus, SOTA Neural MT models may continue to dominate MT use in any enterprise production scenarios for the next 12-15 months except where the highest quality automated translation is required. Currently, LLM MT makes the most sense in settings where high throughput, high volume, and a high degree of automation are not a requirement and where high quality can be achieved with reduced human review costs enabled by language AI.
Translators are already using LLMs for high-resource languages for all the translation-related tasks previously outlined. It is the author’s opinion that there is a transition period where it is quite plausible that both NMT and LLM MT might be used together or separately for different tasks in new LLM-enriched workflows. NMT will likely perform high-volume, time-critical production work as shown below.
In the scenario shown above, information triage is at work. High-volume content is initially processed by an adaptive NMT model, followed by an efficient MTQE process that sends a smaller subset to an LLM for cleanup and refinement. These corrections can be sent back to improve the MT model and increase the quality of the MTQE (not shown in the diagram above).
However, as LLMs get faster and it is easier to automate sequences of tasks, it may be possible to embed both an initial quality assessment and an automated post-editing step together for an LLM-based process to manage.
An emerging trend among LLM experts is the use of agents. Agentic AI and the use of agents in large language models (LLMs) represent a significant evolution in artificial intelligence, moving beyond simple text generation to create autonomous, goal-driven systems capable of complex reasoning and task execution. AI agents use LLMs as their core controller to autonomously pursue complex goals and workflows with minimal human supervision. They potentially combine several key components:
- An LLM core for language understanding and generation
- Memory modules for short-term and long-term information retention
- Planning capabilities for breaking down tasks and setting goals
- Tools for accessing external information and executing actions
- Interfaces for interacting with users or other systems
One approach involves using independent LLM agents to address each of the categories shown below as separate and discrete steps.
The other approach is to integrate these steps into a unified and robust workflow, allowing users to simply submit content and receive the best possible output through an integrated AI-managed process. This integrated workflow would include source cleanup, MTQE, and automated post-editing. There are use cases where both make sense.
Translated is evaluating both approaches to identify the best path forward in different production scenarios.
Agentic AI systems are capable of several advanced capabilities that include:
- Autonomy: Ability to take goal-directed actions with minimal oversight
- Reasoning: Contextual decision-making and weighing tradeoffs
- Adaptive planning: Dynamically adjusting goals and plans as conditions change
- Natural language understanding: Comprehending and following complex instructions
- Workflow optimization: Efficiently moving between subtasks to complete processes
A thriving and vibrant open-source community will be a key requirement for ongoing progress. The open-source community has been continually improving the capabilities of smaller models and challenging the notion that scale is all you need. We see an increase in recent models that are smaller, and more efficient but still capable and are thus often preferred for deployment.
All signs point to an exciting future where the capabilities of technology to enhance and improve human communication and understanding get better, and we are likely to see major advances in bringing an increasing portion of humanity into the digital sphere in productive, positive engagement and interaction.