Understanding Machine Translation Quality
An overview of the techniques that exist today for measuring MT quality, while also dispelling common myths and misconceptions.

Today we live in a world where machine translation (MT) is pervasive, and increasingly a necessary tool for any global enterprise that seeks to understand, communicate and share information with a global customer base.
It is estimated by experts that trillions of words are being translated daily with the aid of the many “free” generic public MT portals worldwide.
This is the first in a series of posts that will explore the issue of MT Quality in some depth, with several goals:
- Explain why MT quality measurement is necessary,
- Share best practices,
- Expose common misconceptions,
- Understand what matters for enterprise and professional use.
While much has been written on this subject already, it has not seemed to have reduced the amount of misunderstanding and confusion around this subject. Thus, there is value in continued elucidation to ensure that greater clarity and understanding are achieved.
So let’s begin.
MT Quality and Why Does It Matter?
Machine Translation (MT) or Automated Translation is a process when computer software “translates” text from one language to another without human involvement.
There are ten or more public MT portals available to do this in the modern era, and additionally, many private MT offerings are available to the modern enterprise to address their large-scale language translation needs. For this reason, the modern global enterprise needs an understanding of the relative strengths and weaknesses of the many offerings available in the marketplace.
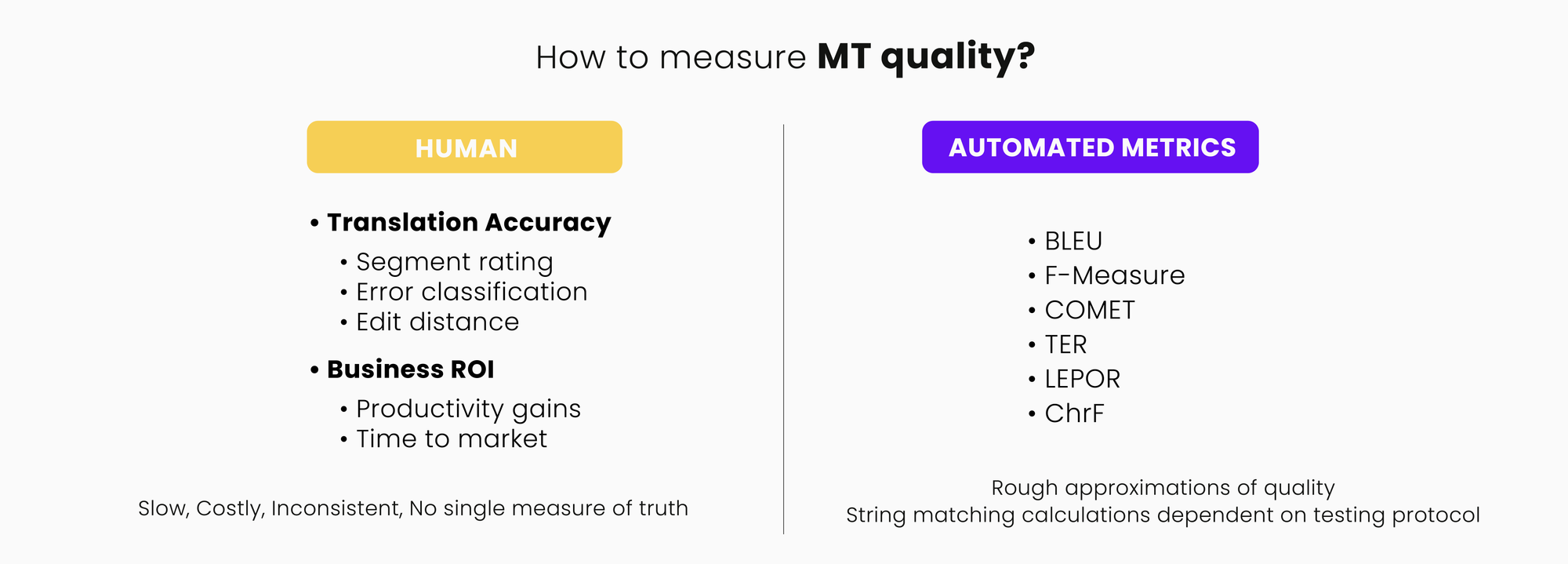
Ideally, the “best” MT system would be identified by a team of competent translators who would run a diverse range of relevant content through the MT system after establishing a structured and repeatable evaluation process. This is slow, expensive, and difficult even if only a small sample of 250 sentences are evaluated.
Thus, automated measurements that attempt to score translation adequacy, fluency, precision, and recall have to be used. They attempt to do what is best done by competent humans. This is done by comparing MT output to a human translation in what is called a Reference Test set. These reference sets cannot provide all the possible ways a source sentence could be correctly translated. Thus, these scoring methodologies are always an approximation of what a competent human assessment would determine, and can sometimes be wrong or misleading.
Thus, identifying the “best MT” solution is not easily done. Consider the cost of evaluating ten different systems on twenty different language combinations with a human team versus automated scores. Even though it is possible to rank MT systems based on scores like BLEU and hLepor, they do not represent production performance. The scores are a snapshot of an ever-changing scene. If you change the angle or the focus the results would change.
A score is not a stable and permanent rating for an MT system. There is no single, magic MT solution that does a perfect job on every document or piece of content or language combination. Thus, the selection of MT systems for production use based on these scores can often be sub-optimal or simply wrong.
Additionally, MT technology is not static: the models are constantly being improved and evolving, and what was true yesterday in quality comparisons may not be true tomorrow.
For these reasons, understanding how the data, algorithms, and human processes around the technology interact is usually more important than any comparison snapshot.
In fact, building expertise and close collaboration with a few MT providers is likely to yield better ROI and business outcomes than jumping from system to system based on transient and outdated quality score-based comparisons.
Two primary groups have an ongoing and continuing interest in measuring MT quality. They are:
- MT developers
- Enterprise buyers and LSPs
They have very different needs and objectives and it is useful to understand why this is so. Measurements that may make sense for developers can often be of little or no value to enterprise buyers and vice versa.
MT Developers
MT developers typically work on one model at a time, e.g.: English-to-French. They will repeatedly add and remove data from a training set, then measure the impact to eventually determine the optimal data needed.
They may also modify parameters on the training algorithms used, or change algorithms altogether, and then experiment further to find the best data/algorithm combinations using instant scoring metrics like BLEU, TER, hLepor, ChrF, and Comet.
While such metrics are useful to developers, they should not be used to cross-compare systems, and have to be used with great care. The quality scores from several (data/algorithm) combinations are calculated by comparing MT output from each of these systems (models) to a Human Reference translation of the same evaluation test data. The highest scoring system is usually considered the best one.
In summary, MT developers use automatically calculated scores that attempt to mathematically summarize overall precision, recall, adequacy, and fluency characteristics of an MT system into a numeric score, This is done to identify the best English-to-French system, as stated in our example, that they can build with available data and computing resources.
However, a professional human assessment may often differ from what these scores say.
In recent years, Neural MT (NMT) models have exposed that using these automated scoring metrics in isolation can lead to sub-optimal choices. Increasingly, human evaluators are also engaged to ensure that there is a correlation between automatically calculated scores and human assessments.
This is because the scores are not always reliable, and human rankings can differ considerably from score-based rankings. Thus, the quality measurement process is expensive, slow, and prone to many procedural errors, and sometimes even deceptive tactics.
Some MT developers test on training data which can result in misleadingly high scores. The optimization process described above is essentially how the large public MT portals develop their generic systems, where the primary focus is on acquiring the right data, using the best algorithms, and getting the highest (BLEU) or lowest (TER) scores.

Enterprise Buyers and LSPs
Enterprise Buyers and LSPs usually have different needs and objectives. They are more likely to be interested in understanding which English-to-French system is the “best” among five or more commercially available MT systems under consideration.
Using automated scores like BLEU, hLepor and TER do not make as much sense in this context. The typical enterprise/LSP is also additionally interested in understanding which system can be “best” modified to learn enterprise terminology and language style.
Optimization around enterprise content and subject domain matters much more, and a comparison of generic (stock) systems can often be useless in the considered professional use context.
Many forget that many business problems require a combination of both MT and human translation to achieve the required level of output quality. Thus, a tightly linked human-in-the-loop (HITL) process to drive MT performance improvements has increasingly become a key requirement for most enterprise MT use cases.
Third-party consultants have compared generic (stock or uncustomized) engines and ranked MT solutions using a variety of test sets that may or may not be relevant to a buyer. These rankings are then often being used to dynamically select different MT systems for different languages, but it is possible and even likely, that they are making sub-optimal choices.
The ease, speed, and cost of tuning and adapting a generic (stock) MT system to enterprise content, terminology, and language style matter much more in this context, and comparisons should only be made after determining this aspect.
However, as generic system comparisons are much easier and less costly to do, TMS systems and middleware that allow MT system selection using these generic evaluation test data scores, often make choices based on irrelevant and outdated data and can thus be sub-optimal. This is a primary reason that so many LSP systems perform so poorly and why MT is so underutilized in this sector.
While NMT continues to gain momentum as the average water level keeps rising, there is still a great deal of naivete and ignorance in the professional translation community about MT quality assessment and MT best practices in general. The enterprise/LSP use of MT is much more demanding in terms of focused accuracy and sophistication in techniques, practices, and deployment variability, and few LSPs are capable or willing to make the investments needed to achieve ongoing competence as the state-of-the-art (SOTA) continues to evolve.
Dispelling MT Quality Misconceptions
1) Google has the “best” MT systems
This is one of the most widely held misconceptions. While Google does have excellent generic systems and broad language coverage, it is not accurate to say that they are always the best.
Google MT is complicated and expensive to customize for enterprise use cases, and there are significant data privacy and data control issues to be navigated. Also, because Google has so much data underlying their MT systems, they are not easily customized by the data volumes that most enterprises or LSPs have available. DeepL is often a favorite of translators, but also has limited customization and adaptation options.
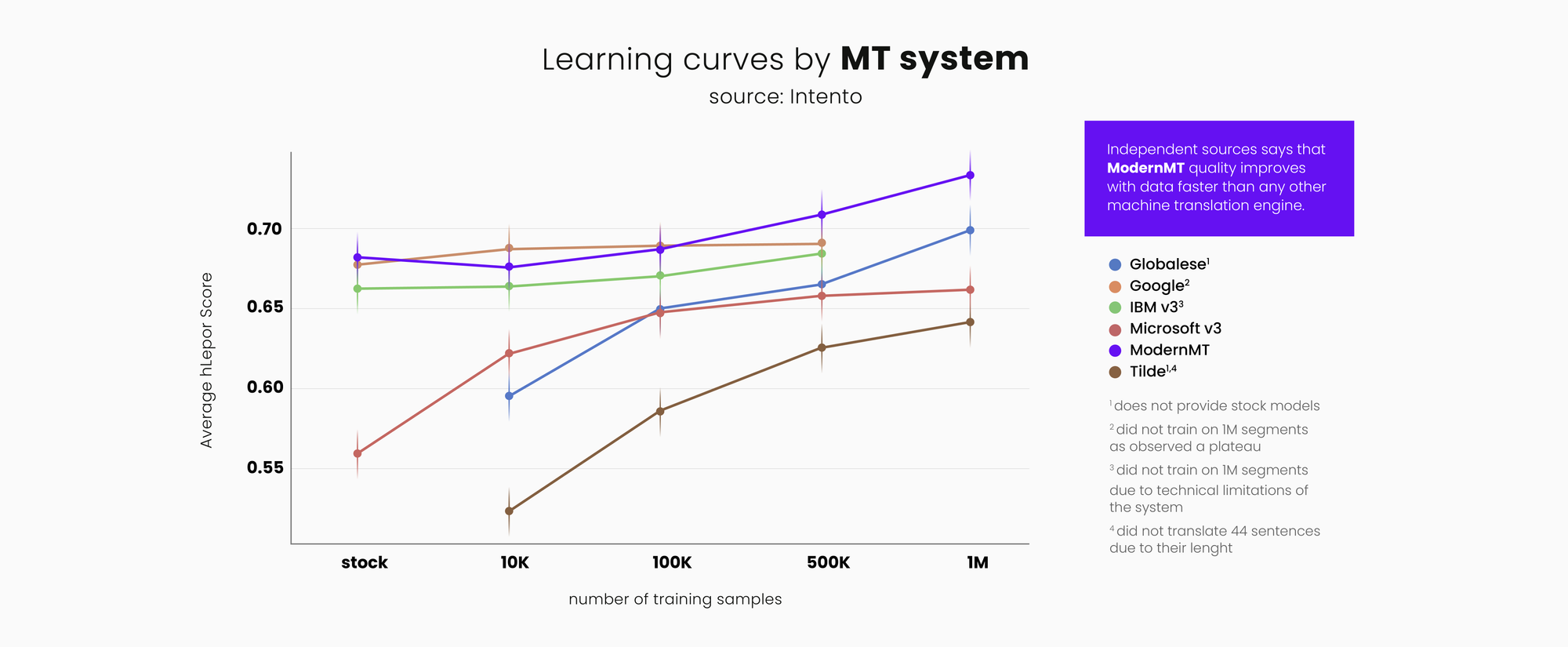
ModernMT is a dynamically adaptive, and continuously learning breakthrough neural MT system. As it is possibly the only MT system that learns and improves with every instance of corrective feedback in real-time, a comparative snapshot based on a static system is even less useful.
A properly implemented ModernMT system will improve rapidly with corrective feedback, and easily outperform generic systems on the enterprise-specific content that matters most. Enterprise needs are more varied, and rapid adaptability, data security, and easy integration into enterprise IT infrastructure typically matter most.
2) MT Quality ratings are static & permanent
MT systems managed and maintained by experts are updated frequently and thus snapshot comparisons are only true for a single test set at a point in time. These scores are a very rough historical proxy for overall system quality and capability, and deeper engagement is needed to better understand system capabilities.
For example, to make proper assessments with ModernMT, it is necessary to actively provide corrective feedback to see the system improve exactly on the content that you are most actively translating now. If multiple editors concurrently provide feedback, ModernMT will improve even faster. These score-based rankings do not tell you how responsive and adaptive an MT system is to your unique data.
TMS systems that switch to different MT systems via API for each language are of dubious value since selections are often based on static and outdated scores. Best practices recommend that efforts to improve an MT systems adaptation to enterprise content, domain, and language style yield higher value than using MT system selection based on embedded scores built into TMS systems and middleware.
3) MT quality ratings for all use cases are the same.
The MT quality discussion needs to evolve beyond targeting linguistic perfection as the final goal, or comparison of BLEU, TER, or hLepor scores, and proximity to human translation.
It is more important to measure the business impact and make more customer-relevant content multilingual across global digital interactions at scale. While it is always good to get as close to human translation quality as possible, this is simply not possible with the huge volumes of content that are being translated today.
There is evidence now that shows that for many eCommerce use scenarios, even gist translations that contain egregious linguistic errors can produce a positive business impact. In information triage scenarios typical in eDiscovery (litigation, pharmacovigilance, national security surveillance) the translation needs to be accurate on key search parameters but not on all the text. Translation of user-generated content (UGC) is invaluable to improving and understanding the customer experience and is also a primary influence on new purchase activity. None of these scenarios requires perfect linguistic quality MT output, to have a positive business impact and drive successful customer engagement.
4) The linguistic quality of MT output is the only way to assess the “best” MT system.
The linguistic quality of MT output is only one of several critical criteria needed for robust evaluation for an enterprise/LSP buyer. Enterprise requirements like the ease and speed of customization to enterprise domain, data security and privacy, production MT system deployment options, integration into enterprise IT infrastructure, overall MT system manageability, and control also need to be considered.
Given that MT is rapidly becoming an essential tool for a globally agile enterprise, we need new ways to measure the quality and value of MT in global CX scenarios. In the scenarios where MT enables better communication, information sharing, and understanding of customer concerns on a global scale, we need new ways to measure success. A closer examination of business impact reveals that the metrics that matter the most would be:
- Increased global digital presence and footprint
- Enhanced global communication and collaboration
- Rapid response in all global customer service/support scenarios
- Productivity improvement in localization use cases to enable more content to be delivered at higher quality
- Improved conversion rates in eCommerce
And ultimately the measure that matters at the executive level is the measurably improved customer experience of every customer in the world.
The reality today is that increasingly larger volumes of content are being translated and used with minimal or no post-editing. The highest impact MT use cases may only post-edit a tiny fraction of the content they translate and distribute.
However, much of the discussion in the industry today still focuses on post-editing efficiency and quality estimation processes that assume all the content will be post-edited.
It is time for a new approach that easily enables tens of millions of words to be translated daily, in continuously learning MT systems that improve by the day and enable new communication, understanding, and collaboration with globally distributed stakeholders.
In the second post in this series, we will dig deeper into BLEU and other automated scoring methodologies and show why competent human assessments are still the most valuable feedback that can be provided to drive ongoing and continuous improvements in MT output quality.
ModernMT is a product by Translated.