Understanding MT Quality: BLEU Scores

The measurement of the overall performance of a machine translation system has always been important for the MT system development community. There has always been a need to quickly understand if an MT system is improving or not during development. There is also a need to understand long-term progress.
However, this has always been a challenge as the tools and measurement systems used are complicated, opaque, and not easily deployed, thus, it is difficult to measure the overall quality capabilities of an MT system with any rigor and robustness.
We should say up front, that the most assured way to determine the best MT system from competing alternatives is to have an assessment done by competent human translators.
Preferably using a team of translators who run a diverse range of relevant content through the MT systems after establishing a structured and repeatable evaluation process. This is slow, expensive, and difficult even if only a small sample of 250 sentences are evaluated.
Thus, we need a cost-effective, quick and dirty approach that can expedite research, development, and rough evaluation in both research and business use settings.
BLEU today is still the most widely used MT quality metric used by most MT researchers across the world in October 2021, even though there have many attempts to displace its prominence with new "improved" metrics like hLepor, TER, Comet, Prism, BertScore, etc. So even though we all understand BLEU is flawed, it remains widely used and is a key measure of MT system performance.
What is a BLEU (Bilingual Evaluation Understudy) score?
The BLEU score is a string-matching algorithm that provides basic output quality metrics for MT researchers and developers. In this post, we review and look more closely at the BLEU score, which is probably the most widely used MT quality assessment metric in use by MT researchers and developers over the last 15 years.
While it is widely understood that BLEU has many flaws, it has not been displaced or replaced by a widely accepted better metric. The MT Summit conference in August 2021, saw that BLEU was the single most frequently used measure of progress and quality improvement in presentations on MT systems development, even though other metrics were presented as "better".
Firstly, we should understand that a fundamental problem with BLEU is that it DOES NOT EVEN TRY to measure “translation quality”, but rather focuses on STRING SIMILARITY (usually to a single human reference).
Unfortunately over the years, people chose to interpret this similarity in a single reference as a measure of the overall quality of an MT system. This is not valid because BLEU scores only reflect how a system performs on the specific set of test sentences used in the test.
As there can be many correct translations, and most BLEU (and many other metrics) tests rely on test sets with only one correct translation reference, it means that it is often possible to score perfectly good translations poorly.
The scores do not reflect the potential performance of the system on other subject material that differs from the specific test material, and all inferences on what the score means should be made with great care, after taking a close look at the existing set of reference test sentences. It is very easy to use and interpret BLEU incorrectly and the localization industry abounds with examples of incorrect, erroneous, and even deceptive use.
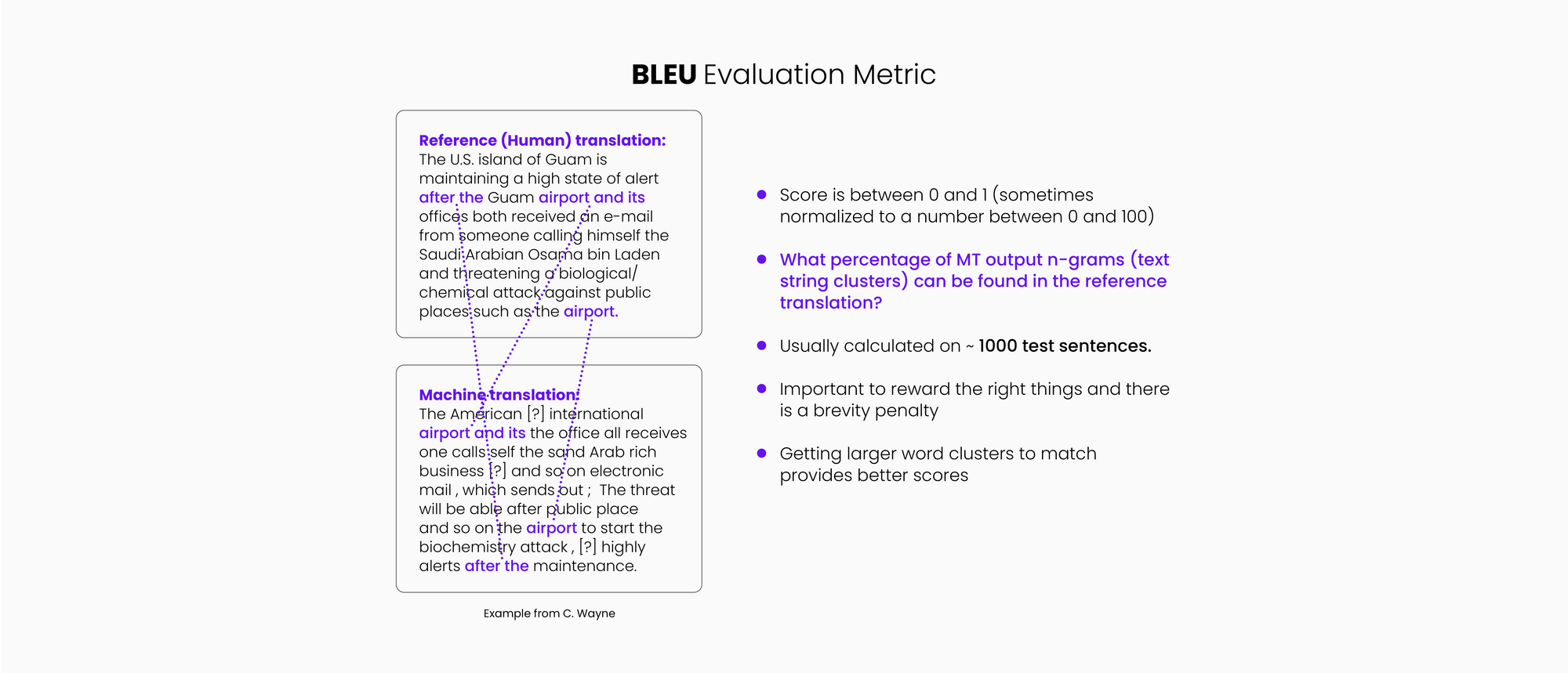
Very simply stated, BLEU is a “quality metric” score for an MT system that is attempting to measure the correspondence between a machine translation output and that of a human with the understanding that "the closer a machine translation is to a professional human translation, the better it is" – this is the central idea behind BLEU. This is also the central idea behind the other "improved" metrics.
Scores are calculated for individual MT-translated segments—generally sentences—by comparing them with a set of good quality human reference translations. Many consider BLEU scores more accurate at a corpus level rather than at a sentence level.
BLEU gained popularity in the early Statistical MT days since it was one of the first MT quality metrics to report a correlation with human judgments of quality. This notion has been challenged often, but after 15 years of attempts to displace it from prominence, the allegedly “improved” derivatives (METEOR, hLepor, TER, chrF, COMET, BertScore) have yet to really unseat its dominance.
BLEU together with human assessment ratings remains the preferred metrics of choice at MT conferences even in the autumn of 2021.
A Closer Examination of BLEU
BLEU is nothing more than a method to measure the similarity between two text strings. The problem with BLEU is most often in the inappropriate way it is used.
To infer that a BLEU score, which has no linguistic consideration or intelligence whatsoever, can predict not only past “translation quality” performance, but also future performance is indeed quite a stretch.
Measuring translation quality is difficult because there is no absolute way to measure how “correct” a translation is. MT is a particularly difficult AI challenge because computers prefer binary outcomes, and translation has rarely if ever only one single correct outcome. Many “correct” answers are possible, and there can be as many “correct” answers as there are translators.
The most common way to measure quality is to compare the output strings of automated translation to a human translation text string of the same sentence. The fact that one human translator will translate a sentence in a significantly different way than another human translator, leads to problems when using these human references to measure “the quality” of an automated translation solution.

The BLEU measure scores a translation on a scale of 0 to 1. The measurement attempts to measure adequacy and fluency in a similar way to a human would, e.g. does the output convey the same meaning as the input sentence, and is the output good and fluent target language? The closer to 1, the more overlap there is with a human reference translation, and thus the better the system is.
In a nutshell, the BLEU score measures how many words overlap, giving higher scores to sequential words.
For example, a string of four words in the translation that match the human reference translation (in the same order) will have a positive impact on the BLEU score and is weighted more heavily (and scored higher) than a one or two-word match.
It is very unlikely that you would ever score 1 as that would mean that the compared output is exactly the same as the reference output. However, it is possible that an accurate translation would receive a low score because it uses different words than the reference used. This problem can be seen in the following examples. If we select any one of these translations for the reference set, all the other correct translations will score lower!


How does BLEU work?
To conduct a BLEU measurement the following data is necessary:
- One or more human reference translations. (This should be data that has NOT been used in building the system (training data) and ideally should be unknown to the MT system developer. It is generally recommended that 1,000+ sentences be used to get a meaningful measurement.) If you use too small a sample set you can sway the score significantly with just a few sentences that match or do not match well.
- Automated translation output of the exact same source data set.
- A measurement utility that performs the comparison and score calculation for you.
- Studies have shown that there is a reasonably high correlation between BLEU and human judgments of quality when properly used.
- BLEU scores are often stated on a scale of 1 to 100 to simplify communication but should not be confused with the percentage of accuracy.
- Even two competent human translations of the exact same material may only score in the 0.6 or 0.7 range as they likely use different vocabulary and phrasing.
- We should be wary of very high BLEU scores (in excess of 0.7) as it is likely we are measuring improperly or overfitting.
A sentence translated by MT may have 75% of the words overlap with one translator’s translation, and only 55% with another translator’s translation; even though both human reference translations are technically correct, the one with the 75% overlap with machine translation will provide a higher “quality” score for the automated translation.
This is somewhat arbitrary. Random string matching scores should not be equated to the overall translation quality capabilities of an MT engine. Therefore, although humans are the true test of correctness, these reference test sets do not provide an objective and consistent measurement for a broadly meaningful notion of quality.
As would be expected using multiple human reference tests will always result in higher scores as the MT output has more human variations to match against. The NIST (National Institute of Standards & Technology) used BLEU as an approximate indicator of quality in its annual MT competitions with four human reference sets to ensure that some variance in human translation is captured, and thus allow more accurate assessments of the MT solutions being evaluated.
The NIST evaluation also defined the development, test, and evaluation process much more carefully and competently, and thus comparing MT systems under their rigor and purview was meaningful. This has not been true for many of the comparisons that were done since, and many recent comparisons are deeply flawed. Some MT vendors may also fudge their scores upwards by adding test set data to the training data.

Why are automated MT quality assessment metrics needed?
Automated quality measurement metrics have always been important to the developers and researchers of data-driven-based MT technology, because of the iterative nature of the MT system development process, and the need for frequent assessments during the development of the system.
These measurements provide rapid feedback on the effectiveness of continuously evolving research and development strategies.
Recently, we see that BLEU and some of its close derivatives (METEOR, hLepor, TER, and Comet) are also often used to compare the quality of competing MT systems in enterprise use settings.
This can be problematic as a “single point quality score” based on publicly sourced news domain sentences is simply not representative of the dynamically changing, customized, and modified potential of an active and evolving enterprise MT system.
Also, such a score does not incorporate the importance of overall business requirements in an enterprise use scenario where other workflow-related, integration, and process-related factors may actually be much more important than small differences in scores.
The definition of useful MT quality in the enterprise use context will vary greatly, depending on the needs of the specific use case.

Most of us agree that competent human evaluation is the best way to understand the output quality implications of different MT systems. However, human evaluation is slower, less objective, and more expensive and thus not viable in many production use scenarios when many comparisons need to be made on a constant and ongoing basis.
Thus, automated metrics like BLEU provide a quick and often dirty quality assessment that can be useful to those who actually understand its basic mechanics. However, they should also understand its basic flaws and limitations and thus avoid coming to over-reaching or erroneous conclusions based on these scores.
There are two very different ways that such scores may be used,
- R&D Mode: In comparing different versions of an evolving system during the development of a single production MT system, and,
- Buyer Mode: In comparing different MT systems from different vendors and deciding which one is the “best” one.
The MT System Research & Development Need: Data-driven MT systems could not be built without using some kind of automated measurement metric to measure ongoing progress. MT system builders are constantly trying new data management techniques, algorithms, and data combinations to improve systems, and thus need quick and frequent feedback on whether a particular strategy is working or not.
It is necessary to use some form of standardized, objective, and relatively rapid means of assessing quality as part of the system development process in this technology. If this evaluation is done properly, the tests can also be useful over a longer period to understand how a system evolves over many years.
The MT Buyer Need: As there are many MT technology options available today, BLEU and its derivatives are sometimes used to select "optimal" MT systems. The use of BLEU in this context is much more problematic and prone to drawing erroneous conclusions as often comparisons are being made between apples and oranges.
The most common error in interpreting BLEU is the lack of awareness and understanding that there is a positive bias towards one MT system because it has already seen and trained on the test data, or has been used to develop the test data set.
Rapid and straightforward customizability is emerging as a much more important driver of successful outcomes in most enterprise use cases and thus we need to be asking, are we really measuring the right things?

Problems with BLEU
While BLEU is very useful to those who build and refine MT systems, its value as an effective way to compare totally different MT systems is much more limited and needs to be done very carefully, if done at all, as it is easily and often manipulated to create the illusion of superior performance.
“CSA Research and leading MT experts have pointed out for over a decade that these metrics [BLEU] are artificial and irrelevant for translation production environments. One of the biggest reasons is that the scores are relative to particular references. Changes that improve performance against one human translation might degrade it with respect to another… Approaches that emphasize usability and user acceptance take more effort than automatic scores but point the way toward a useful and practical discussion of MT quality. “
Excerpt from a CSA Blog on BLEU Misuse, April 2017
There are several criticisms of BLEU that should also be understood if you are to use the metric effectively. BLEU only measures direct word-by-word similarity and looks to match and measure the extent to which word clusters in two sentences or documents are identical. Accurate translations that use different words may score poorly since there is no match in the human reference.
There is no understanding of paraphrases and synonyms so scores can be somewhat misleading in terms of overall accuracy. You have to get the exact same words used in the human reference translation to get credit e.g.
"Wander" doesn't get partial credit for "stroll," nor "sofa" for "couch."
Also, nonsensical language that contains the right phrases in the wrong order can score high. e.g.
"Appeared calm when he was taken to the American plane, which will to Miami, Florida" would get the very same score as: "was being led to the calm as he was would take carry him seemed quite when taken".
A more recent criticism identifies the following problems:
- It is an intrinsically meaningless score
- It does not consider the meaning
- It admits too many bad variations – meaningless and syntactically incorrect variations can score the same as good variations
- It admits too few variations – it treats synonyms as incorrect
- Small score differences are difficult to interpret accurately
- More reference translations do not necessarily help
These and other problems are described in this article and this critical academic review. The core problem is that word-counting scores like BLEU and its derivatives - the linchpin of the many machine-translation competitive comparisons - don't even recognize well-formed language, let alone translated meaning.
Here is a more recent post that I recommend, as it very clearly explains other metrics, and shows why it also still makes sense to use BLEU in spite of its many problems.
For post-editing work assessments there is a growing preference for using edit distance scores to more accurately reflect the effort involved, even though it too, is far from perfect.
The problems are further exacerbated with the Neural MT technology which can often generate excellent translations that are quite different from the reference and thus score poorly. Thus, many have found that lower (BLEU) scoring NMT systems are clearly preferred over higher-scoring SMT systems when human evaluations are done.
There are some new metrics (hLEPOR, ChrF, SacreBLEU, BERTScore, COMET, Prism) attempting to replace BLEU, but none have gathered any significant momentum yet, and the best way to evaluate NMT system output today is still with well-structured human assessments.
What is BLEU useful for?
Modern MT systems are built by “training” a computer with examples of human translations. As more human-translated data is added, systems should generally get better in quality. Often, new data can be added with beneficial results, but sometimes new data can cause a negative effect especially if it is noisy or otherwise “dirty”.
Thus, to measure if progress is being made in the development process, the system developers need to be able to measure the quality impact rapidly and frequently to make sure they are improving the system and are in fact making progress.
BLEU does have some strengths, of course. The most relevant ones for people working in NLP have to do with how convenient it is for researchers.
- It’s fast and easy to calculate, especially compared to having human translators rate model output.
- It’s ubiquitous. This makes it easy to compare your model to benchmarks on the same task.
Unfortunately, this very convenience has led to people overapplying it, even for tasks where it’s not the best choice of metric.
The following is the guidance that Google provides for those using BLEU measurements. We should understand that this guidance is only valid for a properly specified and performed blind test.
However, as a rough guideline, the following interpretation of BLEU scores (expressed as percentages rather than decimals) might be helpful.
| BLEU Score | Interpretation |
|---|---|
| < 10 | Almost useless |
| 10 - 19 | Hard to get the gist |
| 20 - 29 | The gist is clear, but has significant grammatical errors |
| 30 - 40 | Understandable to good translations |
| 40 - 50 | High quality translations |
| 50 - 60 | Very high quality, adequate, and fluent translations |
| > 60 | Quality often better than human |
The following color gradient can be used as a general scale interpretation of the BLEU score:
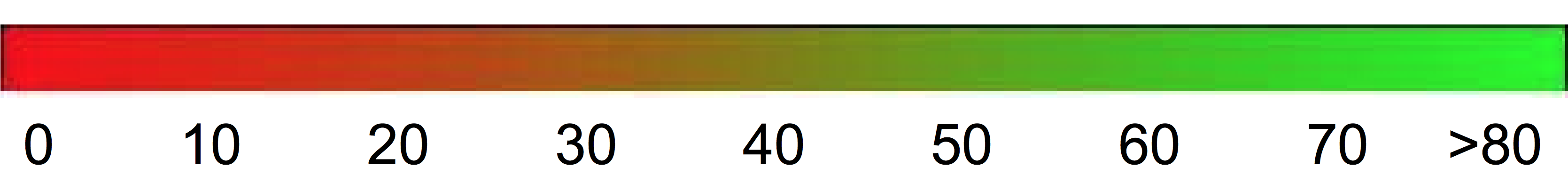
What is BLEU not useful for?
BLEU scores are always very directly related to a specific “test set” and a specific language pair. Thus, BLEU should not be used as an absolute measure of translation quality because the BLEU score can vary even for a single language depending on the test and subject domain. In most cases comparing BLEU scores across different languages is meaningless unless very strict protocols have been followed.
Trying to compare BLEU scores across different corpora and languages is strongly discouraged. Even comparing BLEU scores for the same corpus but with different numbers of reference translations can be highly misleading.
Because of this, it is always recommended to use human translators to verify the accuracy of the metrics after systems have been built. Also, best practices recommend that one always vet the BLEU score readings with human assessments before production use.
In competitive comparisons, it is important to carry out the comparison tests in an unbiased, scientific manner to get a true view of where you stand against competitive alternatives.
The “test set” should be unknown (“blind”) to all the systems that are involved in the measurement. This is something that is often violated in many widely used comparisons today.
If a system is trained with the sentences in the “test set” it will obviously do well on the test but probably not as well on data that it has not seen before. Many recent comparisons score MT systems on news-domain (the most easily available data). A good score on news-domain may not be especially meaningful for an enterprise use case that is heavily focused on IT, pharma, travel, or any domain other than news.
However, in spite of all the limitations identified above, BLEU continues to be the basic metric used by most, if not all MT researchers today. Though, now, best practices suggest the use of human evaluation on smaller sets of data to validate BLEU scores.
The MT community has found that supposedly improved metrics like METEOR, hLEPOR, COMET, and other metrics have not really gained any momentum. BLEU and its flaws and issues are more clearly understood, and thus more reliable, especially if used together with supporting human assessments.
Also, many buyers today realize that MT system performance on their specific subject domains and translatable content for different use cases matters much more than how generic systems might perform on the news or other unspecified and opaque test data.
In upcoming posts in this series, we will continue to explore the issue of MT quality from a broad enterprise needs perspective. While having a sense of how an MT system will perform on your enterprise data is valuable, it is even more useful to understand how easily and quickly a system can be molded to function within high-value business workflows to impact global business initiatives.
ModernMT is a product by Translated.