The Challenge of MT with Non-English Language Pairs
Evidence of superior performance from MT systems built by direct modeling between languages and avoiding the use of pivoting through English

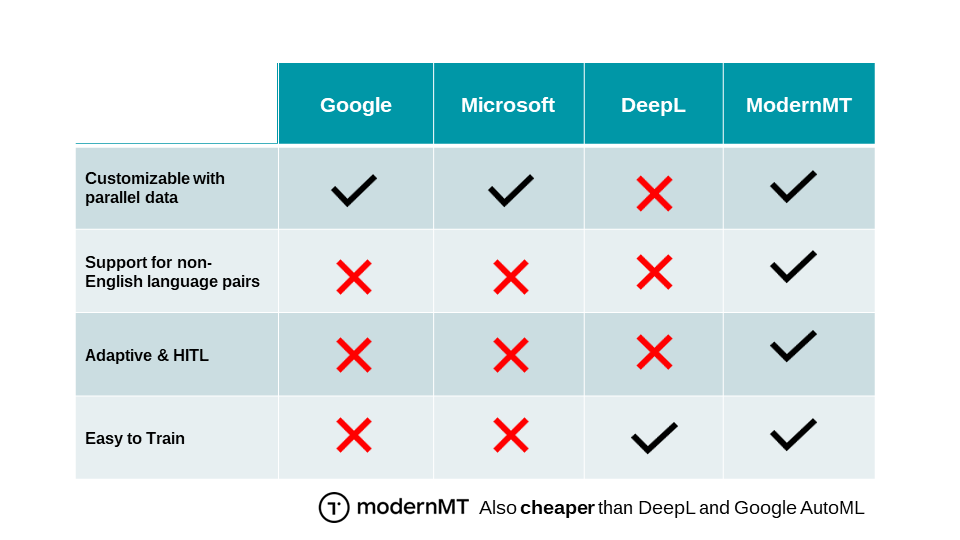
As the momentum for widespread Enterprise MT use continues, we are increasingly seeing more interest in the use of MT across language pairs that do not involve or include English. This can be a problem sometimes as much of the long-term development of MT technology has been very English-centric.
Thus, MT most often works best in language combinations that go from or into English, e.g., EN > FR, EN > DE, IT > EN, ZH > EN, or JP > EN. It has also generally (though not strictly) been true that X > EN tends to yield better results than EN > X. This is because there simply is more data around English than any other language, both bilingual text, and especially monolingual text.
But as the global internet population changes, the importance of English declines, and we see that there is growing interest in developing optimized MT technology between languages that do not include English. This is true across the globe as MT is seen as a technology that can help to build momentum within regional trade zones.
The need for translations between non-English pairs has typically been managed by going through English as a pivot language. Thus, DE > IT would be accomplished in two steps, first using a DE > EN system and then taking that output and using an EN > IT system. This two-step journey also results in a degradation in output quality as described below. This is beginning to change and there are an increasing number of direct language combinations being developed including the language pairs described in the Comparis case study presented below.
It has often surprised me that some in the translation industry use automated back translation as a way to check MT quality, as from my vantage point it introduces similar problems to what pivoting MT does. MT back translation by definition should result in further deterioration of output quality as MT output will often be something less than a perfect translation.
This point seems to evade many who advocate this method of evaluation, so let us clarify with some mathematics as math is one of the few conceptual frameworks available to man where the proof has meaningful certainty. If one has a “perfect MT system” then the Source and Target segments should be very close to each other if not the same. The perfect score would be 1, which would mean that all the information in the source would be present in the target. Thus, anything less than perfect would be less than 1. So mathematically we could state this as:

Thus, if we do a formal evaluation of the output of various MT systems (each language direction should be considered a separate system) and find that the following table is true for our samples by running 5,000 sentences through various MT conversions (translations) and scoring each MT translation (conversion) as a percentage “correct” in terms of linguistic accuracy and precision.
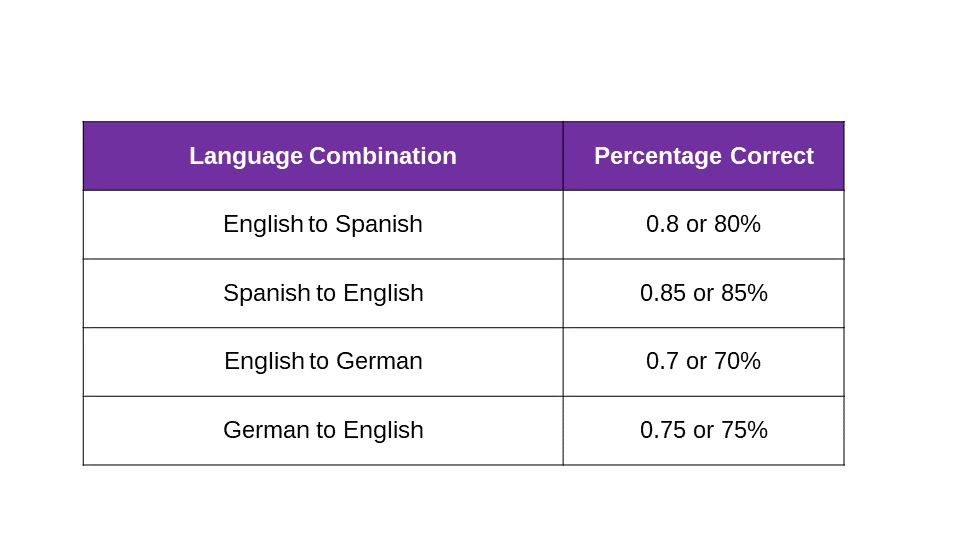
This evaluation gives us a sense of how these systems are likely to perform with any new source material. But if we now chain the results (to replicate the pivot effect) by making the output of one, the input (source) of the other, we will find that results are different and get continually worse e.g.
ES > EN > DE = .85 x .70 = 0.595 or 59.5% correct
EN > DE > EN = .7 x .75 = 0.525 or 52.5% correct
Of course, the real results will not follow this kind of mathematical precision and may actually be slightly better or worse. However, in general, this degradation will hold. So now if we take our example and run it through multiple iterations, we should expect to see a very definite degradation of the output as we see below.
EN > ES > EN (from MT) > DE > EN = .8 x .85 x .7 x .75 = 35.7%
This is exactly the strategy that has been used by content creators in what can be called MT-based humor. The translation degradation works even better if multiple iterations are done with a larger variety of languages. Even more so when the languages are very different linguistically.
Here is an example where you can see the source at the top of the video and the multi-pivoted translation at the bottom.
Here is a more recent example that shows that even all the recent advances in NMT have not managed to reduce the degradation much if enough pivoting is done.
So, while it is clear that simple two-step pivoting is not as damaging, it does suggest that it is worth enabling direct translations between non-English language combinations whenever possible.
The following case study that describes the Comparis experience is helpful to understand the benefit of avoiding pivoting whenever possible and provides insight into some of the issues that came up in a comparative evaluation.
The Comparis Case Study
(written by Daniele Giulianelli)
Comparis is the #1 consumer empowerment platform in Switzerland: we help our users find the products that most fit their needs in different fields: health insurance, car insurance, mortgage, consumer finance, and many more. Since Switzerland is “multilingual by design” (it has 4 national languages), translation and localization have a very important role in our company.
Our content is mostly written in German, and then gets translated into French and Italian (in their Swiss locale), and into English:
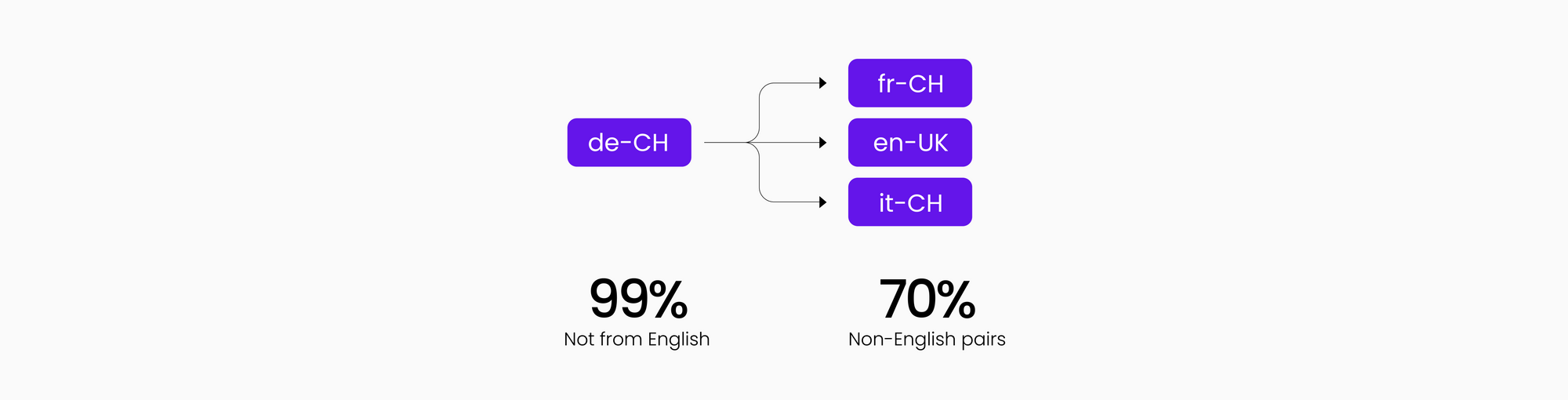
When starting a Machine Translation program, we had to face two main issues: very in-domain content and small locales. Thus, generic MT was not really an option, since the training data sets mostly refer to the “bigger” locales (Germany, France, Italy). This would have resulted in a huge post-editing effort and probably no real efficiency gain from the use of MT.
The path to customization is not always easy. After talking to some providers, it became clear that with our Translation Memories (about 150,000 segments per language pair) it would have been hard to have a significant impact on the quality of the MT output. Also, a traditional “bulk” customization can be pretty expensive. And in most cases, there is no customization option for non-English language pairs, which are by far the most important for us.
That’s how we chose to try ModernMT since it gave us the opportunity to:
- Customize “on the fly” by just adding TMX files.
- Customize directly between non-English language pairs without pivoting.
We evaluated different MT solutions using ModelFront: the first candidates were Google Translate, DeepL, and ModernMT. For the latter, we just used one year (2020) of Translation Memory as a training data set for customization. ModernMT proved to be the best solution, even with this minimal customization:

Here are a couple of examples to illustrate how ModernMT performs in our locales:
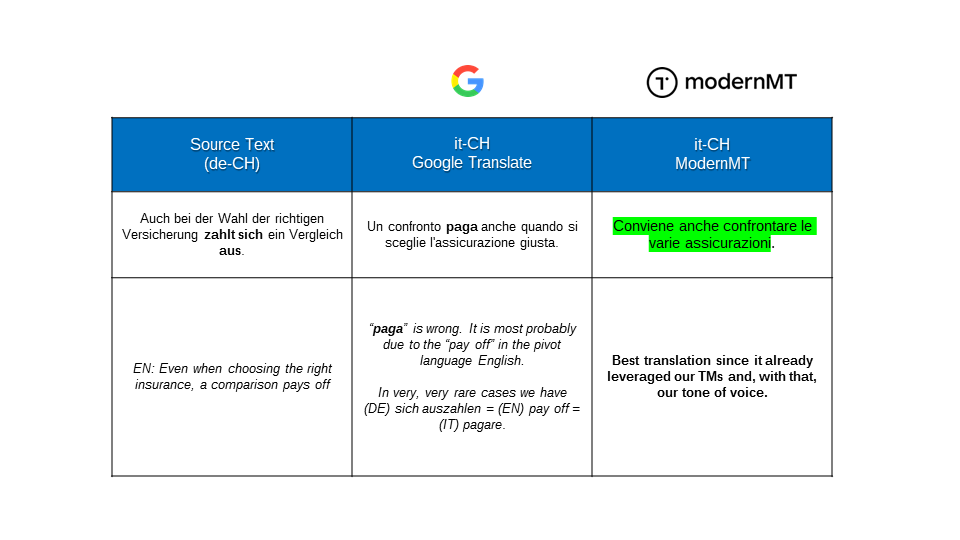
Customizing with bilingual translation memory files (TMXs) without pivoting also proved to be very efficient for MT performance on in-domain topics:
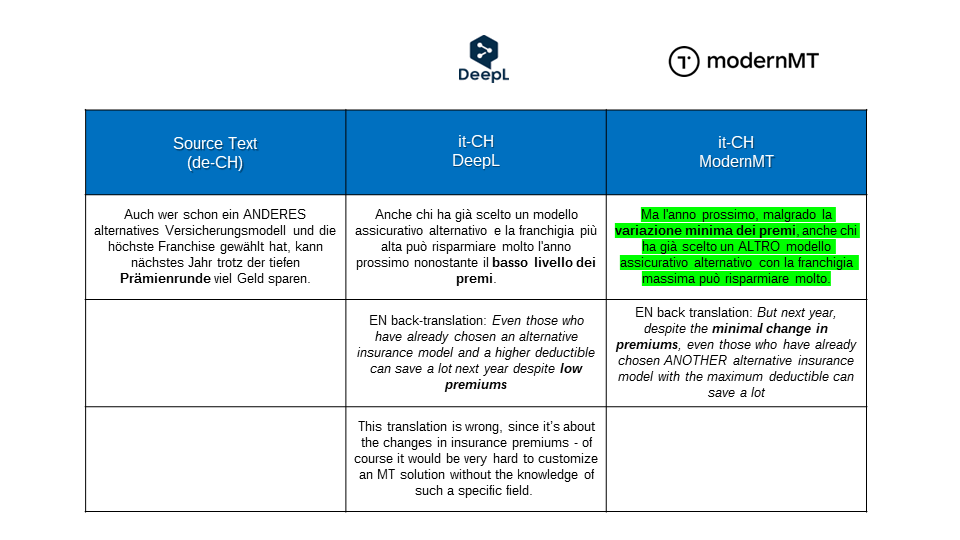
After analyzing these results, we decided to move forward with ModernMT. Another reason for choosing this provider has been of course their adaptive technology. Right from the start we noticed that our machine translation learns our terminology and our style while we post-edit the MT output.
We were even able to solve our peculiar issue with the tone of voice for Swiss Italian: which is neither formal nor informal. Just impersonal - so instead of writing “you should compare insurances” we have “it is important to compare insurances”. It took just a couple of weeks to have it function in our MT output as we wanted.
All things considered, we observed almost a 30% productivity boost in our team across all languages. And we are confident that this trend will continue, and that our post-editing effort will diminish. This will give us more resources in our team to work on non-MT tasks like advertising, slogans, and SEO optimization.
Daniele Giulianelli, has been in the localization industry for over 10 years, focused on finance and insurance. He is currently the Leader of Translations and Product Owner Newsroom at Comparis, working to establish best practices for the challenges of in-house language services, especially focusing on MT and multilingual SEO.

ModernMT is a product by Translated.