ModernMT Introduces Trust Attention To Boost MT Quality
ModernMT introduces Trust Attention which allows an MT engine to prioritize more trustworthy data and have this data influence model behavior more heavily. These new innovations provide global enterprises with a superior platform to build highly-tuned enterprise-specific translation engines.

ModernMT: A History of Innovation and Evolution
Neural machine translation (NMT) has had impressive evolutionary progress over the last five years, showing continually improving performance in accuracy. This progress is specially marked and clear with the dynamically adaptive NMT models like ModernMT, where small amounts of ongoing corrective expert feedback results in continuously improving MT output quality.
The historical track record with ModernMT has been so impressive that it did not seem unreasonable to point out that ModernMT's performance across billions of samples and many languages were approaching singularity in production-use scenarios. This is a point at which human editors are unable to tell whether the sample is coming from a human or machine since they are so close in quality and style.
NMT technology continues to evolve and improve with recent updates that provide much richer and more granular document-level contextual awareness. Document-level adaptation in machine translation has been a core design intention with ModernMT from the outset. This originally involved referencing similar sentences in translation memories and using these to influence new translation requests.
Despite the success and pioneering nature of this approach, early implementations faced challenges: translators struggled with issues such as gender bias and inconsistent terminology due to the distance between the segment they were working on and its related context.
By taking into account all edits within an individual document, even those in completely different or distant segments, the MT model is now able to provide document-specific translation suggestions. This development significantly reduces the need for repeated corrections of elements such as pronouns. This has greatly eased the amount of corrective work needed to address gender bias errors and modify incorrect terminology.
The Emergence of LLM-Based Translation Models
In the summer of 2023, we are at an interesting junction in the development of AI-based language translation technology, where we now see that Large Language Models (LLMs) are also an emerging technological approach to having machines perform the language translation task. LLMs are particularly impressive in handling idioms and enhancing the fluency of machine translations.
However, at this point, there are still serious latency, high training and inference costs, and most importantly trustworthiness issues with output produced by Generative AI models like GPT-4. These issues will need to be addressed for Gen AI models to be viable in production-use translation settings.
The AI product team at Translated continues to research and investigate the possibilities for continued improvement of pure NMT models, hybrid NMT and Gen AI models, as well as pure Gen AI models. Special consideration is given to ensure that any major improvements made in existing NMT model technology can also be leveraged in the future with potentially production-use capable Gen AI translation models.
AI systems are trained on large datasets found on the internet, data that can be of varied quality and reliability. If the data used for training is biased or of poor quality, it can lead to biased or unreliable AI outputs, and we have seen that one of the biggest obstacles to the widespread use of Gen AI in mission-critical applications has been the high levels of problematic and fluent, but untrustworthy output.
Better data validation and verification can indeed improve the trustworthiness of AI output. Data validation involves ensuring that the data used to train and evaluate AI models is accurate, consistent, and representative of the real-world scenarios the AI system will encounter. This can be done through data cleaning, data preprocessing techniques, and careful selection of training data.
The Importance of Data Quality
With this in mind, ModernMT Version 7, introduces a significant upgrade to its core adaptive machine translation (MT) system. This new version introduces Trust Attention, a novel technique inspired by how human researchers prioritize information from trusted sources and the V 7 model preferentially uses identified trustworthy data both in training and inference.
This innovation is the first of a long-term thematic effort focused on improving data quality being undertaken at Translated, to ensure that data quality and trustworthiness is a pervasive and comprehensive attribute of all new translation AI initiatives.
Translated has realized from a large number of independent evaluations and internal testing over the years, that this focus on data quality enables ModernMT to compare favorably in quality performance evaluations to many other better-funded public generic MT engines produced by Google, Microsoft, and others.
They have developed a robust data governance framework to define data quality standards, processes, and roles over the last decade. This helps create a culture of data quality and ensures that data management practices are aligned with organizational efficiency goals and technology improvements.
This culture, together with close long-term collaboration with translators ensures that ongoing data replenishment is of the highest quality and systematically identifies and removes lower-quality data. Finally, regularly measuring and monitoring data quality metrics helps to identify and address potential issues before they impact AI performance.
Trust Attention is possible because of the long-term investment in developing a data-quality culture that produces the right data to feed innovation in new AI technologies.
While it is common practice in the industry to use automated algorithm-driven methods to drive data validation and verification practices, Translated’s 20 years of experience working with human translators show that human-verified data is the most trustworthy data available to drive the learning of language AI models.
This human-verified data foundation is precisely the most influential driver of preferential learning in the ModernMT Version 7 models. Automated cleaning and verification are valid ways to enhance data quality in machine learning applications, but 10 years of experience show that human-verified data provide a performance edge that is not easily matched by large-scale automated cleaning and verification methods.
Human quality assessments made comparing ModernMT V6 output versus V7 output show that the use of Trust Attention improves translation quality by as much as 42% of the time. It is interesting to note that many high-resource languages like Spanish, Chinese, and Italian also saw major improvements near the 30% range in human evaluations.
Human evaluations and judgments are corroborated by concurrent BLEU and COMET score measurements which are also used to ensure that conclusions being drawn by introducing new technology are accurate and trustworthy.
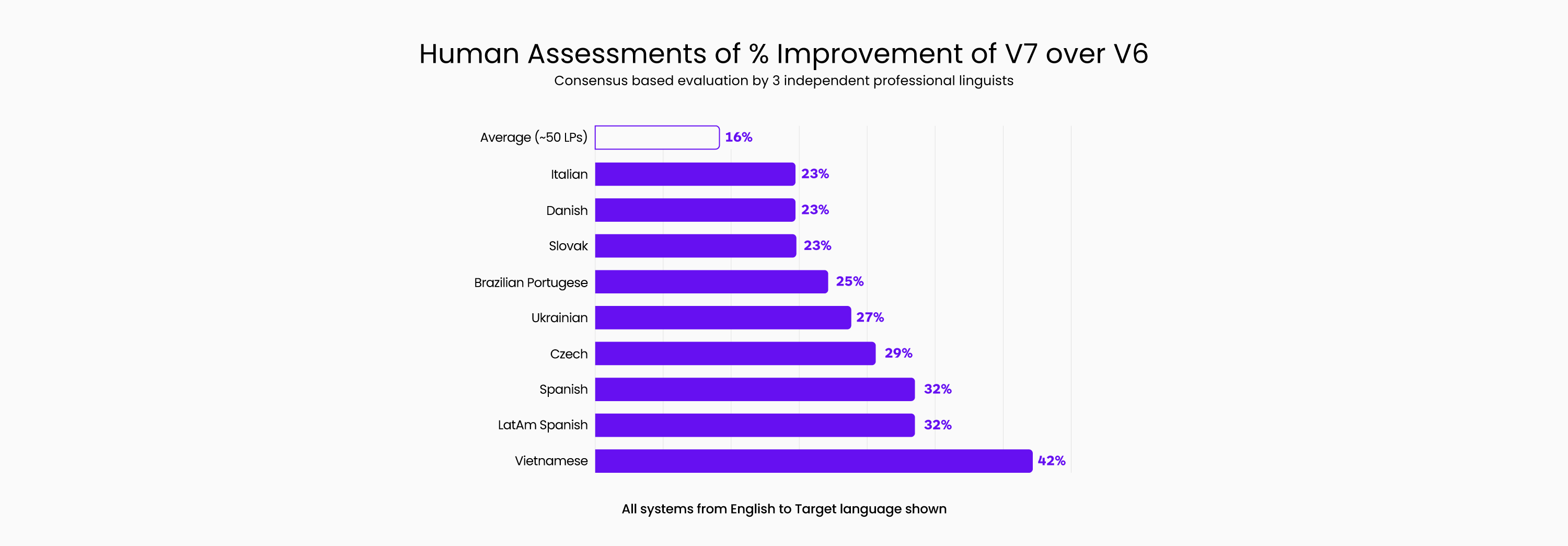
The following is a sample of MT output from the ModernMT V7 system compared to the previous V6. Three independent professional reviewers were shown two randomized samples of a translation of the same source segment and asked to judge if one was better or not. The chart above shows how often the V7 version was preferred by language.
Examples below show sample sentences from English to Brazilian Portuguese and Simplified Chinese.

“If 80 percent of our work is data preparation, then ensuring data quality is the important work of a machine learning team.”
Andrew Ng, Professor of AI at Standford University and founder of DeepLearning.AI

How is Trust Attention Different?
“Garbage in, garbage out” (GIGO) is a concept in computing and artificial intelligence (AI) that highlights the importance of input data quality. It means that if the input data to a system, such as an AI model or algorithm, is of poor quality, inaccurate, or irrelevant, the system’s output will also be of poor quality, inaccurate, or irrelevant.
This concept is particularly significant in the context of AI models which use machine learning and deep learning models, and rely heavily on the data used for training and validation. If the training data is biased, incomplete, or contains errors, the AI model will likely produce unreliable or biased results.
All Data Is Not Equally Important
Traditional MT systems generally are not able to distinguish between trustworthy data and lower-quality training material during the training process, and typically all the data has equal weight. Thus, high-quality data and high-volume noisy data can have essentially the same amount of impact on how a translation model will perform.
Trust Attention allows an engine to prioritize more trustworthy data and have this data influence model behavior more heavily.
ModernMT now uses a first-of-its-kind weighting system to enable primary learning from high-quality, trusted, and verified data – translations performed and/or reviewed by professional translators – over unverified data that is acquired from the Web.
As with adaptive MT, Translated looked to established human practices to develop this new technique. In any serious research, humans collect and sift through multiple information sources to identify and assign preferential status to the most trustworthy and reliable data sources.
ModernMT V7 similarly identifies the most valuable training data and prioritizes its learning based on certified and verified data by modeling this human behavior. This certification and verification is not an automated machine-led process, rather it is an expert human validation that raises the trustworthiness of the data.
This focus on prioritizing the use of trusted, verified data is a major step forward in the development of enterprise-focused MT technology. The efforts made to identify and build repositories of high-quality data will also be useful in the future if there is indeed a shift to Gen AI-based language translation models.
Today, there is considerable discussion regarding the application of large language models in translation. While the traditional NMT models seem to perform much better on the accuracy dimension, though they can be less fluent than humans, LLMs tend to emphasize and often win on fluency, even though these models often produce misleading output due to hallucinations (generative fabrication).
Trust Attention methodology deployed in LLMs, will also enhance the accuracy of generative models, reducing the chances of random fabrication and hallucination errors. This could set the stage for an emerging era of new machine translation methodologies, one that combines the accuracy of dynamic adaptive NMT with the fluency of Gen AI models.
ModernMT Version 7 also introduces a data-cleaning AI that minimizes the likelihood of hallucinations, making it valuable for companies seeking greater accuracy in high-volume automated translation use cases, and is also useful for translators integrating MT into their workflow.
John Tinsley, VP of AI Solutions at Translated, added, "We are confident that these new data validation and verification techniques can also improve accuracy in generative AI systems, paving the way for the next generation of machine translation."
The introduction of this new approach is a major step forward for companies seeking greater accuracy in the translation of large volumes of content or requiring a high degree of customization of the MT engine, as well as for translators integrating MT into their workflow.
The combined impact of these multiple innovations provides global enterprises with a superior platform to rapidly transform generic engines into highly-tuned enterprise-specific translation engines.
"ModernMT's ability to prioritize higher quality data to improve the model is the most significant leap forward in machine translation since the introduction of dynamic adaptivity five years ago," said Marco Trombetti, CEO of Translated. "This exciting innovation opens up new opportunities for companies to use MT to take their global customer experience to the next level. It will also help translators increase productivity and revenue."
All Translated clients will benefit from the improved quality of the new MT model, resulting in faster project turnaround times. Translators working with Translated will experience the power of the new model through Matecat, Translated's free, web-based, AI-powered CAT tool. Translators using an officially supported CAT tool (Matecat, memoQ, Blackbird, and Trados) with an active ModernMT license will also experience the power of the new model. The Version 7 capabilities have already been released for the major languages and the rollout will continue across all 200 supported languages shortly.
ModernMT is a product by Translated.