The Human-In-The-Loop
What is HITL and why it is crucial to the future of Machine Translation.

We live in an age where artificial intelligence (AI) is a term that is used extensively in conversations both in our personal and professional lives. In most cases, the term AI refers to specialized machine learning (ML) applications that “acquire knowledge” through a process called deep learning.
While great progress has been made in many ML cases, we also realize now that machine learning alone is unlikely to completely solve challenging problems, especially in natural language processing (NLP). The neural machine translation (NMT) capabilities today are impressive in contrast to historical MT offerings but still fall short of competent human translation.
Neural MT “learns to translate” by looking closely (aka as "training") at large datasets of human-translated data. Deep learning is self-education for machines; you feed the system huge amounts of data, and it begins to discern complex patterns within the data.
But despite the occasional ability to produce human-like outputs, ML algorithms are at their core only complex mathematical functions that map observations to outcomes. They can forecast patterns that they have previously seen and explicitly learned from. Therefore, they’re only as good as the data they train on and start to break down as real-world data starts to deviate from examples seen during training.
Neural MT has made great progress indeed but is far from having solved the translation problem. Post-editing is still needed in professional settings and no responsible language services company would depend entirely on MT without human oversight or review.
We hear regularly about "big data" that is driving AI progress, but we are finding more and more cases where the current approach of deep learning and adding more data is not enough. The path to progress is unlikely to be brute force training of larger neural networks with deeper layers on more data.
Whilst deep learning excels at pattern recognition, it’s very poor at adapting to changing situations when even small modifications of the original case are encountered, and often has to be re-trained with large amounts of data from scratch. This is one reason we see so little production use of MT amongst LSPs.
In most cases, the AI learning process happens upfront and only takes place in the development phase. The model that is developed is then brought onto the market as a finished program. Continuous “learning” is neither planned nor does it always happen after a model is put into production use. This is also true of most public MT systems. While these systems are updated periodically, they are not easily able to learn and adapt to new, ever-changing production requirements.
Machine learning progress still falls short of human performance in NLP
Recently there has been much fanfare around huge pre-trained language model-based initiatives like BERT and GPT-3. This involves training a neural network model on an enormous amount of data and then adapting (“fine-tune”) the model to a bunch of more specific NLP tasks that require classification, sequence labeling, or similar digesting of text, e.g., named entity recognition, question answering, sentiment analysis. GPT-3 can even generate some human-sounding textual responses to questions.
Researchers at Stanford have been most vocal in claiming that this is a “sweeping paradigm shift in AI”. They have coined a new term, “Foundation Models” to characterize this shift, but are being challenged by many experts.
Some examples of the counter view :
Jitendra Malik, a renowned expert in computer vision at Berkeley, said, “I am going to take a ... strongly critical role when we talk about them as the foundation of AI ... These models are castles in the air. They have no foundations whatsoever.”
Georgia Tech professor Mark Riedl wrote on Twitter “Branding very large pre-trained neural language models as “foundation” models is a brilliant … PR stunt. It presupposes them as inevitable to any future in AI”. But that doesn’t make it so.
The reality is that foundation model demos, at least in their current incarnations. are more like parlor tricks than genuine intelligence. They work impressively well some of the time but also frequently fail, in ways that are erratic, unsystematic, and even foolish. One recent model, for example, mistook an apple with the word “iPod” on a piece of paper for an actual iPod.
The initial enthusiasm for GPT-3 has been followed by increasing concern as people have realized how these systems are prone to producing obscenity, prejudiced remarks, misinformation, and so forth. Some experts fear that GPT-3-like capabilities could even become the engine for a massively scaled misinformation engine creating crap/mediocre content to instigate increased societal dysfunction and polarization. Large pre-trained statistical models can do almost anything, at least enough for a proof of concept, but there is little that they can do reliably—precisely because they skirt the foundations that are actually required.
OpenAI who believe in the scaling hypothesis is supposedly working on GPT-4 which they say will have 100 Trillion Parameters — 500+ times the size of GPT-3, in a presumed attempt to achieve AGI. But critics are skeptical that increasing data and scale alone will be the answer.
Foundational AI models are a dead end: they will never yield systems that understand; their maniacal focus on “moar data!” is superficial; they grow at the expense of ignoring better architectures. — Grady Booch
Stuart Russell, professor at Berkeley and AI pioneer, argues that “focusing on raw computing power misses the point entirely […] We don’t know how to make a machine intelligent — even if it were the size of the universe.” Deep learning isn’t enough to achieve AGI.
We have seen that these two opposing views have also been true with machine translation. There were significant advances when we moved from Rule-Based MT to Statistical MT initially. The improvements plateaued after an initial forward leap, and then we discovered that more data is not always better, and this happened again with Neural MT.
There are some who believe that NMT will replace human translators, but the reality in professional translation is not quite as shiny. Today we are much more aware that data quality and the “right data” matters more than volume alone. Human oversight is mandatory for most professional translations. Some say that setting up an active learning and corrective feedback process is a better way forward than brute force data and computing resource application.
What is human-in-the-loop (HITL) based human-machine collaboration?
Human-in-the-loop (HITL), is the process of leveraging the power of the machine and enabling high-value human intelligence interactions to create continuously improving machine learning-based AI models. Active learning generally refers to the humans handling low confidence units and feeding improvements back into the model. Human-in-the-loop is broader, encompassing active learning approaches as well as the creation of data sets through human labeling.
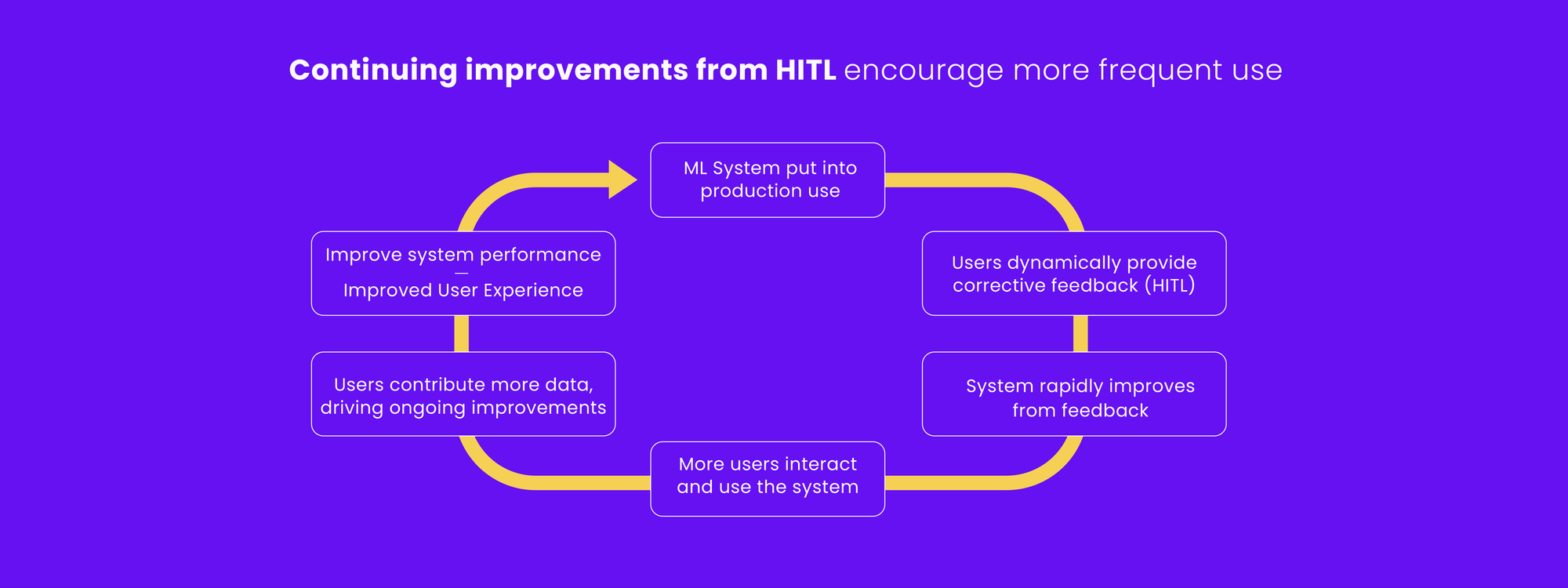
HITL describes the process when the machine is unable to solve a problem based on initial training data alone and needs human intervention to improve both the training and testing stages of building an algorithm. Properly done, this creates an active feedback loop allowing the algorithm to give continuously better results with ongoing use and feedback.
ML “learns” by collecting “experience” from the contents of exemplary data sets, arranging these “experiences”, developing a complex model from it, and finally gaining “knowledge” from the patterns and laws that have emerged. In other words, machines learn by being trained — fed with data sets. Thus, “learning” is only as good as the data that they learn from. The computer encodes this learning into an algorithm using neural net deep learning techniques. This algorithm is then used to convert new input data with the learned patterns embedded in the algorithms to hopefully generate acceptable and useful output. Public MT that produces “gist quality” output is an example of widely used NLP AI that “translates” trillions of words a day.
With language translation, the critical training data is translation memory. However, the truth is that there is no existing training data set (TM) that is so perfect, complete, and comprehensive as to produce an algorithm that consistently produces perfect translations.
While some MT systems can produce compelling output in a limited area of use (usually on new data that is similar to the training material used), the professional use of MT often requires ongoing human review and post-editing before widespread dissemination and business use of translated content.
Language is always evolving and words have innumerable ways of being combined to preclude the possibility that the machine algorithm will have seen every possible combination.
With most MT systems, ongoing “learning” is neither planned nor does it happen often after the initial development phase.
Also, adapting large generic models to unique enterprise use cases is often fraught with difficulty because developers lack insight into the volume, nature, and quality of the underlying base data. While some systems may have periodic updates as new chunks of training data become available, in the interim post-editors are forced to repeatedly correct the same type of errors, over and over again. Thus, we see that many LSPs and translators tend to be averse to using MT widely and do so with reluctance.
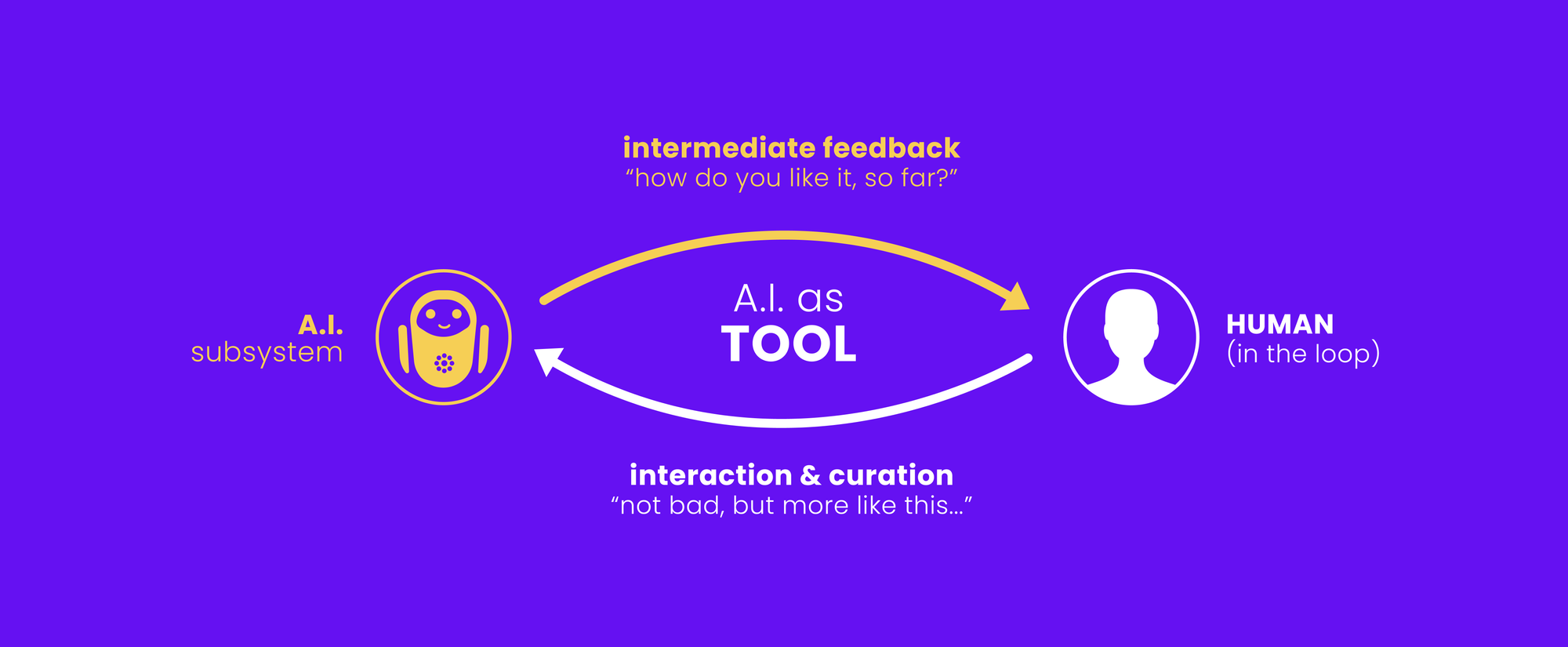
AI models don't make predictions with 100% confidence as their "understanding" of data is largely based on statistics, which lacks the concept of certainty as humans use it in practice. To account for this inherent algorithmic uncertainty, some AI systems like ModernMT allow humans to directly interact with it to actively contribute relevant new learning.
As a consequence of this interaction (feedback), the machine keeps adjusting its "view of the world" and adapts to the new learning. This works much like you would teach a child when it points at a cat saying "woof woof" – through repeated correction ("No, that's a cat"), the child will learn to connect to the updated learning.
Human-in-the-loop aims to achieve what neither a human being nor a machine can achieve on their own. When a machine isn’t able to solve a problem, humans step in and intervene. This process results in the creation of a continuous feedback loop that produces output that is useful to the humans using the system.
With constant feedback, the algorithm learns and produces better results over time. Active and continuous feedback to improve existing learning and create new learning is a key element of this approach.
As Rodney Brooks, the co-founder of iRobot said in a post entitled - An Inconvenient Truth About AI: "Just about every successful deployment of AI has either one of two expedients: It has a person somewhere in the loop, or the cost of failure, should the system blunder, is very low."
In the translation context, with ModernMT, this means that the system is designed from the ground up to actively receive feedback and rapidly incorporate this into the existing model on a daily or even hourly basis.
This rapid and continuous feedback and learning loop produce better MT output. This is in contrast to most MT models where corrective data is collected over many months or years and laboriously re-trained to learn from the corrective feedback, often with limited success as opaque baseline data dominates the model’s predictive behavior.
HITL refers to systems that allow humans to give direct feedback to a model for predictions below a certain level of confidence. This approach allows ModernMT to address the problem of quickly acquiring the “right” data for the specific translation task at hand. HITL within the ModernMT framework allows the system to perform best on the material that is currently in focus.
The HITL approach also enables ModernMT to rapidly acquire competence in sparse data situations as many enterprise use scenarios do not initially have the right training data available a priori.
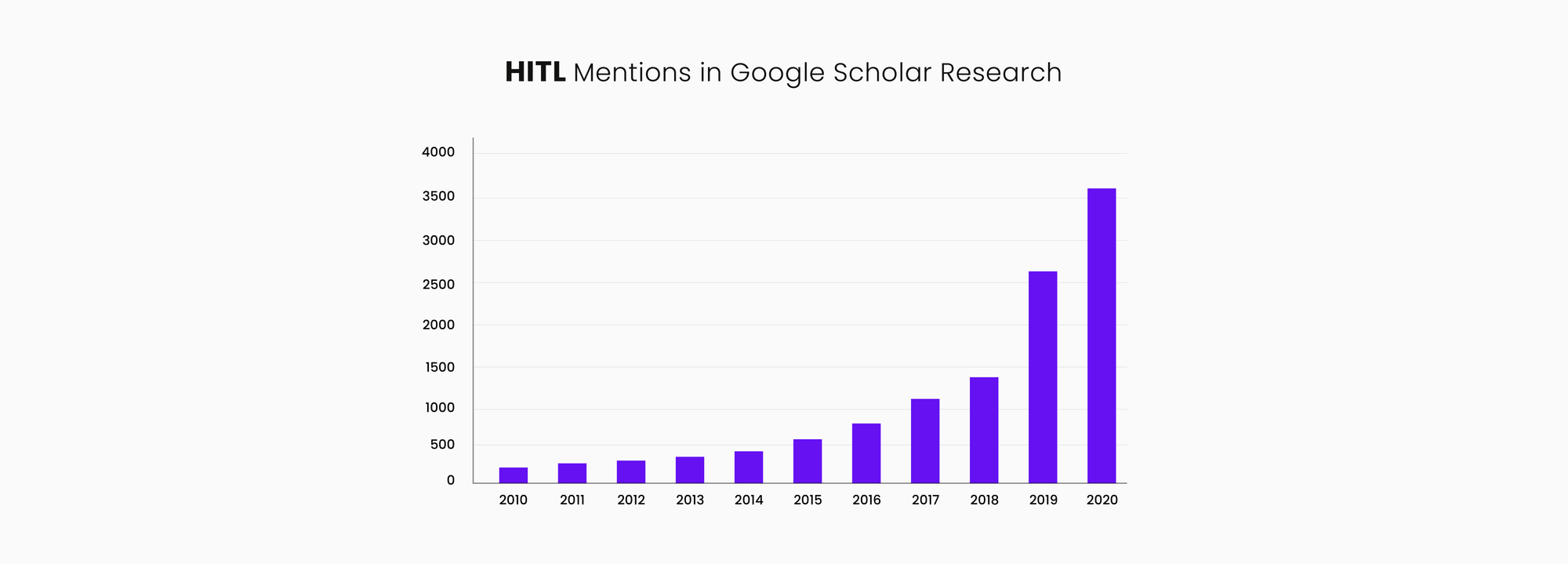
An examination of the increasing research interest in HITL can be obtained through a Google Scholar search with the keywords: “human-in-the-loop” and “machine learning”. As the use of machine learning proliferates, there is an increasing awareness that humans working together with machines in an active learning contribution mode can often outperform the possibilities of machines or humans alone.
Effective HITL implementations allow the machine to capture an increasing amount of highly relevant knowledge and enhance the core application as ModernMT does with MT.
While there are some who talk about AI "sentience" and singularity the reality is more sobering. Something anyone who tries to ask Alexa, Siri, or the latest Chatbot a question that goes beyond the simplest form can testify to. Humans learn how to make Alexa work some of the time for simple things but mostly have to hear the AI say that they do not understand the question when probed for anything beyond simple database lookups.
AI lacks a theory of mind, common sense and causal reasoning, extrapolation capabilities, and a body, and so it is still extremely far from being “better than us” at almost anything slightly complex or general.
This also suggests that humans will remain at the center of complex, knowledge-based AI applications even though the way humans work will continue to change. The future is more likely to be about how to make AI be a useful assistant than it is about replacing humans. In language translation, we see that HITL MT systems like ModernMT enable humans to address a much broader range of translation challenges that can add significant value to a growing range of enterprise use cases.
ModernMT: Humans and Machines, Hand in Hand
ModernMT is a highly interactive and engaged MT architecture that has been built and refined over a decade with active feedback and learning from both translators and MT researchers. ModernMT is used intensively in all the production translation work done by Translated Srl. and was a functioning HITL machine learning system before the term was even coined.
This long-term engagement with translators and continuous feedback-driven improvement process also results in creating a superior training data set over the years. This superior data enables users to have an efficiency and quality advantage that is not easily or rapidly replicated. This is also the reason why ModernMT does so consistently well in third-party MT system comparisons, even though evaluators do not always measure its performance optimally. ModernMT simply has more informed translator feedback built into the system.
ModernMT is an "Instance-Based Adaptive MT" platform. This means that it can start adapting and tuning the MT output to a customer subject domain immediately, without a batch customization phase. There is no long-running (hours/days/weeks) data preparation and pre-training process needed upfront.
There is also no need to wait and gather a sufficient volume of corrective feedback to update and improve the MT engine on an ongoing basis. It is learning all the time. This also makes it an ideal MT capability for any LSP or translator or any competent bilingual human who can provide ongoing feedback to the system.
In the typical MT development scenario across the world, we see that MT developers and translators have minimal communication and interaction. The typical PEMT workflow involves low-paid translators/editors correcting MT output with little to no say in how the MT system works and responds to feedback. In the typical MT scenario, humans are the downstream clean-up crew after MT produces an initial messy draft.
Typical use of MT has infrequent human feedback once a model is produced and large data volumes of corrective feedback have to be collected slowly to properly train and update models to learn customer-specific language patterns, style, and terminology.
This is in dramatic contrast to the ModernMT development scenario. There is an active and ongoing dialog between MT developers and translators on an ongoing and continuous basis. This makes developers more aware of translator frustrations/needs and also teaches translators to provide actionable and concrete feedback on system output.
The understanding of the translation task and resulting directives that ongoing translator feedback brings to the table is an ingredient that most current MT systems lack.
Corrective feedback given to the MT system is dynamic and continuous and can have an immediate impact on the next sentence produced by the MT system. Over the years the ModernMT product evolution has been driven by changes to identify and reduce post-editing and translation cognition effort rather than optimizing BLEU scores as most other MT developers have done.
Recently, in sales presentations at MT Summit, several MT vendors claimed to have “human-in-the-loop” MT systems when presenting traditional PEMT workflows. However, it is much easier to add those words on a slide than to implement the key set of functional requirements and capabilities that make HITL a reality.
Expert MT use is a result of the right data, the right process, and ML algorithms. In the localization use case, the "right" process is particularly important. “Like much of machine intelligence, the real genius [of deep learning] comes from how the system is designed, not from any autonomous intelligence of its own. Clever representations, including clever architecture, make clever machine intelligence,” Roitblat writes.
ModernMT is an example of a superior implementation that brings key elements together compellingly and consistently to solve enterprise translation problems efficiently and at scale.
The following is a summary of features in a well-designed HITL system, such as the one underlying ModernMT:
- Easy setup and startup process for any and every new adapted MT system
- Active and continuous corrective feedback is rapidly processed so that translators can see the impact of corrections in real-time.
- An MT system that is continuously training and improving with this feedback (by the minute, day, week, month).
- Active communication and collaboration between translators and MT research and development to address high-friction problems for translators.
- An inherently superior and continuously improving foundational training data set progressively vetted by humans.
- Ongoing system evaluation from human feedback and assessment rather than from automated metrics like BLEU, hLepor, Comet, or TER.
- Tightly integrated into the foundational CAT tools used by translators who provide the most valuable system-enhancing feedback.
- Translators WANT-TO-USE MT for productivity benefits, unlike many PEMT scenarios where translators do NOT want to work with and actively avoid MT.
- Multiple points of feedback and system improvement data build collaborative momentum.
As we look to the future of MT technology, it is increasingly apparent that progress will be more likely to come from HITL contributions than from algorithms, computing power, or even new large-scale data acquisition.
MT systems like ModernMT that easily and dynamically engage informed human feedback will learn what matters most to the production use of MT and improve specifically on the most relevant data.
The future of localization is likely to be increasingly a "machine-first, human-optimized" model, and dynamically better, more responsive machine performance will likely result in more positive and successful human interaction and engagement.
Until we come to the day where perfect training data sets are available to train MT, properly designed feedback processing and dynamic model updating capabilities like ModernMT are much more likely to deliver the best and most useful MT performance.
ModernMT is a product by Translated.